导读:用户标签是个性化推荐、计算广告、金融征信等众多大数据业务应用的基础,它是原始的用户行为数据和大数据应用之间的桥梁,本文会介绍用户标签的构建方法,也就是用户画像技术。
 01用户画像概述1. 什么是用户画像现代交互设计之父Alan Cooper很早就提出了Persona的概念:Persona是真实用户的虚拟代表,是建立在一系列真实数据之上的目标用户模型,用于产品需求挖掘与交互设计。通过调研和问卷去了解用户,根据他们的目标、行为和观点的差异,将他们区分为不同的类型,然后从每种类型中抽取出典型特征,赋予名字、照片、人口统计学要素、场景等描述,就形成了一个Persona。Persona就是最早对用户画像的定义,随着时代的发展,用户画像早已不再局限于早期的这些维度,但用户画像的核心依然是真实用户的虚拟化表示。在大数据时代,用户画像尤其重要。我们通过一些手段,给用户的习惯、行为、属性贴上一系列标签,抽象出一个用户的全貌,为广告推荐、内容分发、活动营销等诸多互联网业务提供了可能性。它是计算广告、个性化推荐、智能营销等大数据技术的基础,毫不夸张地说,用户画像是大数据业务和技术的基石。用户画像的核心工作就是给用户打标签,标签通常是人为规定的高度精炼的特征标识,如年龄、性别、地域、兴趣等。由这些标签集合能抽象出一个用户的信息全貌,如图10-1所示是某个用户的标签集合,每个标签分别描述了该用户的一个维度,各个维度相互联系,共同构成对用户的一个整体描述。
01用户画像概述1. 什么是用户画像现代交互设计之父Alan Cooper很早就提出了Persona的概念:Persona是真实用户的虚拟代表,是建立在一系列真实数据之上的目标用户模型,用于产品需求挖掘与交互设计。通过调研和问卷去了解用户,根据他们的目标、行为和观点的差异,将他们区分为不同的类型,然后从每种类型中抽取出典型特征,赋予名字、照片、人口统计学要素、场景等描述,就形成了一个Persona。Persona就是最早对用户画像的定义,随着时代的发展,用户画像早已不再局限于早期的这些维度,但用户画像的核心依然是真实用户的虚拟化表示。在大数据时代,用户画像尤其重要。我们通过一些手段,给用户的习惯、行为、属性贴上一系列标签,抽象出一个用户的全貌,为广告推荐、内容分发、活动营销等诸多互联网业务提供了可能性。它是计算广告、个性化推荐、智能营销等大数据技术的基础,毫不夸张地说,用户画像是大数据业务和技术的基石。用户画像的核心工作就是给用户打标签,标签通常是人为规定的高度精炼的特征标识,如年龄、性别、地域、兴趣等。由这些标签集合能抽象出一个用户的信息全貌,如图10-1所示是某个用户的标签集合,每个标签分别描述了该用户的一个维度,各个维度相互联系,共同构成对用户的一个整体描述。
 ▲图10-1 用户标签集合2. 为什么需要用户画像Cooper最初建立Persona的目的是让团队成员将产品设计的焦点放在目标用户的动机和行为上,从而避免产品设计人员草率地代表用户。产品设计人员经常不自觉地把自己当作用户代表,根据自己的需求设计产品,导致无法抓住实际用户的需求。往往对产品做了很多功能的升级,用户却觉得体验变差了。在大数据领域,用户画像的作用远不止于此。如图10-2所示,用户的行为数据无法直接用于数据分析和模型训练,我们也无法从用户的行为日志中直接获取有用的信息。而将用户的行为数据标签化以后,我们对用户就有了一个直观的认识。同时计算机也能够理解用户,将用户的行为信息用于个性化推荐、个性化搜索、广告精准投放和智能营销等领域。
▲图10-1 用户标签集合2. 为什么需要用户画像Cooper最初建立Persona的目的是让团队成员将产品设计的焦点放在目标用户的动机和行为上,从而避免产品设计人员草率地代表用户。产品设计人员经常不自觉地把自己当作用户代表,根据自己的需求设计产品,导致无法抓住实际用户的需求。往往对产品做了很多功能的升级,用户却觉得体验变差了。在大数据领域,用户画像的作用远不止于此。如图10-2所示,用户的行为数据无法直接用于数据分析和模型训练,我们也无法从用户的行为日志中直接获取有用的信息。而将用户的行为数据标签化以后,我们对用户就有了一个直观的认识。同时计算机也能够理解用户,将用户的行为信息用于个性化推荐、个性化搜索、广告精准投放和智能营销等领域。
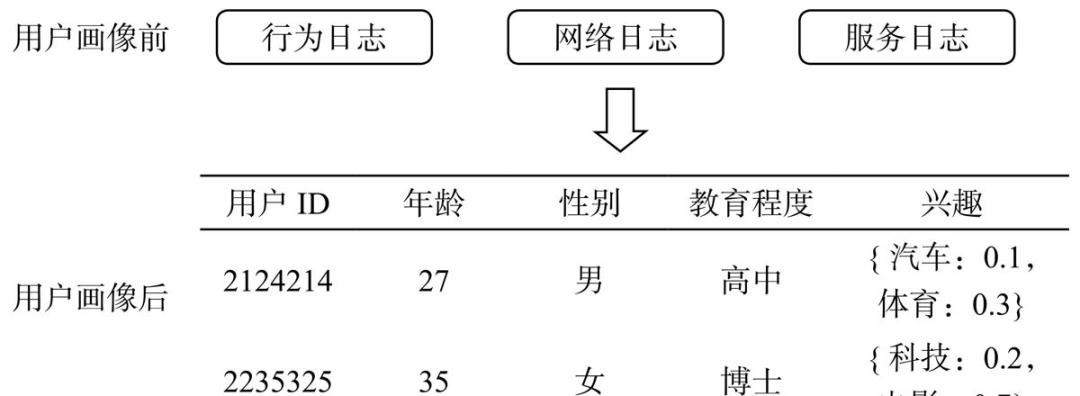 ▲图10-2 用户标签化对于一个产品,尤其是互联网产品,建立完善的用户画像体系,有着重大的战略意义。基于用户画像能够构建一套分析平台,用于产品定位、竞品分析、营收分析等,为产品的方向与决策提供数据支持和事实依据。在产品的运营和优化中,根据用户画像能够深入用户需求,从而设计出更适合用户的产品,提升用户体验。02 用户画像流程用户画像的核心工作就是给用户打“标签”,构建用户画像的第一步就是搞清楚需要构建什么样的标签,而构建什么样的标签是由业务需求和数据的实际情况决定的。下面介绍构建用户画像的整体流程和一些常用的标签体系。1. 整体流程对构建用户画像的方法进行总结归纳,发现用户画像的构建一般可以分为目标分析、标签体系构建、画像构建三步,下面详细介绍每一步的工作。1)目标分析用户画像构建的目的不尽相同,有的是实现精准营销,增加产品销量;有的是进行产品改进,提升用户体验。明确用户画像的目标是构建用户画像的第一步,也是设计标签体系的基础。目标分析一般可以分为业务目标分析和可用数据分析两步。目标分析的结果有两个:一个是画像的目标,也就是画像的效果评估标准;另一个是可用于画像的数据。画像的目标确立要建立在对数据深入分析的基础上,脱离数据制定的画像目标是没有意义的。2)标签体系构建分析完已有数据和画像目标之后,还不能直接进行画像建模工作,在画像建模开始之前需要先进行标签体系的制定。对于标签体系的制定,既需要业务知识,也需要大数据知识,因此在制定标签体系时,最好有本领域的专家和大数据工程师共同参与。在制定标签体系时,可以参考业界的标签体系,尤其是同行业的标签体系。用业界已有的成熟方案解决目标业务问题,不仅可以扩充思路,技术可行性也会比较高。此外,需要明确的一点是:标签体系不是一成不变的,随着业务的发展,标签体系也会发生变化。例如电商行业的用户标签,最初只需要消费偏好标签,GPS标签既难以刻画也没有使用场景。随着智能手机的普及,GPS数据变得易于获取,而且线下营销也越来越注重场景化,因此GPS标签也有了构建的意义。3)画像构建基于用户基础数据,根据构建好的标签体系,就可以进行画像构建的工作了。用户标签的刻画是一个长期的工作,不可能一步到位,需要不断地扩充和优化。一次性构建中如果数据维度过多,可能会有目标不明确、需求相互冲突、构建效率低等问题,因此在构建过程中建议将项目进行分期,每一期只构建某一类标签。画像构建中用到的技术有数据统计、机器学习和自然语言处理技术(NLP)等,如图10-3所示。具体的画像构建方法会在本文后面的部分详细介绍。
▲图10-2 用户标签化对于一个产品,尤其是互联网产品,建立完善的用户画像体系,有着重大的战略意义。基于用户画像能够构建一套分析平台,用于产品定位、竞品分析、营收分析等,为产品的方向与决策提供数据支持和事实依据。在产品的运营和优化中,根据用户画像能够深入用户需求,从而设计出更适合用户的产品,提升用户体验。02 用户画像流程用户画像的核心工作就是给用户打“标签”,构建用户画像的第一步就是搞清楚需要构建什么样的标签,而构建什么样的标签是由业务需求和数据的实际情况决定的。下面介绍构建用户画像的整体流程和一些常用的标签体系。1. 整体流程对构建用户画像的方法进行总结归纳,发现用户画像的构建一般可以分为目标分析、标签体系构建、画像构建三步,下面详细介绍每一步的工作。1)目标分析用户画像构建的目的不尽相同,有的是实现精准营销,增加产品销量;有的是进行产品改进,提升用户体验。明确用户画像的目标是构建用户画像的第一步,也是设计标签体系的基础。目标分析一般可以分为业务目标分析和可用数据分析两步。目标分析的结果有两个:一个是画像的目标,也就是画像的效果评估标准;另一个是可用于画像的数据。画像的目标确立要建立在对数据深入分析的基础上,脱离数据制定的画像目标是没有意义的。2)标签体系构建分析完已有数据和画像目标之后,还不能直接进行画像建模工作,在画像建模开始之前需要先进行标签体系的制定。对于标签体系的制定,既需要业务知识,也需要大数据知识,因此在制定标签体系时,最好有本领域的专家和大数据工程师共同参与。在制定标签体系时,可以参考业界的标签体系,尤其是同行业的标签体系。用业界已有的成熟方案解决目标业务问题,不仅可以扩充思路,技术可行性也会比较高。此外,需要明确的一点是:标签体系不是一成不变的,随着业务的发展,标签体系也会发生变化。例如电商行业的用户标签,最初只需要消费偏好标签,GPS标签既难以刻画也没有使用场景。随着智能手机的普及,GPS数据变得易于获取,而且线下营销也越来越注重场景化,因此GPS标签也有了构建的意义。3)画像构建基于用户基础数据,根据构建好的标签体系,就可以进行画像构建的工作了。用户标签的刻画是一个长期的工作,不可能一步到位,需要不断地扩充和优化。一次性构建中如果数据维度过多,可能会有目标不明确、需求相互冲突、构建效率低等问题,因此在构建过程中建议将项目进行分期,每一期只构建某一类标签。画像构建中用到的技术有数据统计、机器学习和自然语言处理技术(NLP)等,如图10-3所示。具体的画像构建方法会在本文后面的部分详细介绍。
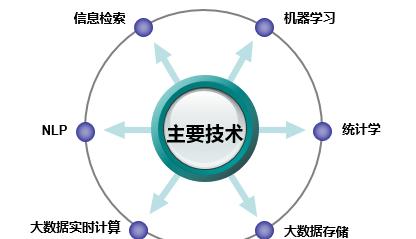 ▲图10-3 用户画像的构建技术2. 标签体系目前主流的标签体系都是层次化的,如图10-4所示。首先标签分为几个大类,每个大类再进行逐层细分。在构建标签时,只需要构建最下层的标签,就能够映射出上面两级标签。上层标签都是抽象的标签集合,一般没有实用意义,只有统计意义。例如我们可以统计有人口属性标签的用户比例,但用户有人口属性标签,这本身对广告投放没有任何意义。
▲图10-3 用户画像的构建技术2. 标签体系目前主流的标签体系都是层次化的,如图10-4所示。首先标签分为几个大类,每个大类再进行逐层细分。在构建标签时,只需要构建最下层的标签,就能够映射出上面两级标签。上层标签都是抽象的标签集合,一般没有实用意义,只有统计意义。例如我们可以统计有人口属性标签的用户比例,但用户有人口属性标签,这本身对广告投放没有任何意义。
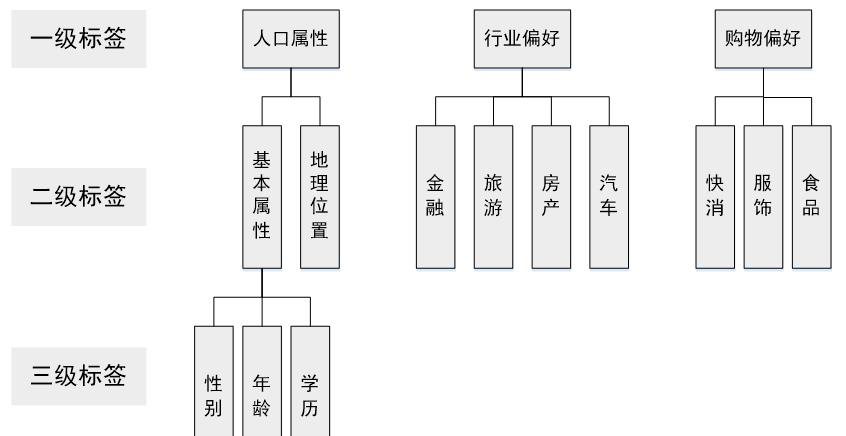 ▲图10-4 互联网大数据领域常用标签体系用于广告投放和精准营销的一般是底层标签,对于底层标签有两个要求:一个是每个标签只能表示一种含义,避免标签之间的重复和冲突,便于计算机处理;另一个是标签必须有一定的语义,方便相关人员理解每个标签的含义。此外,标签的粒度也是需要注意的,标签粒度太粗会没有区分度,粒度过细会导致标签体系太过复杂而不具有通用性。下文列举了各个大类常见的底层标签。人口标签:性别、年龄、地域、教育水平、出生日期、职业、星座兴趣特征:兴趣爱好、使用App/网站、浏览/收藏内容、互动内容、品牌偏好、产品偏好社会特征:婚姻状况、家庭情况、社交/信息渠道偏好消费特征:收入状况、购买力水平、已购商品、购买渠道偏好、最后购买时间、购买频次最后介绍一下构建各类标签的优先级。对此需要综合考虑业务需求、构建难易程度等,业务需求各有不同,这里介绍的优先级排序方法主要依据构建的难易程度和各类标签的依存关系,优先级如图10-5所示。
▲图10-4 互联网大数据领域常用标签体系用于广告投放和精准营销的一般是底层标签,对于底层标签有两个要求:一个是每个标签只能表示一种含义,避免标签之间的重复和冲突,便于计算机处理;另一个是标签必须有一定的语义,方便相关人员理解每个标签的含义。此外,标签的粒度也是需要注意的,标签粒度太粗会没有区分度,粒度过细会导致标签体系太过复杂而不具有通用性。下文列举了各个大类常见的底层标签。人口标签:性别、年龄、地域、教育水平、出生日期、职业、星座兴趣特征:兴趣爱好、使用App/网站、浏览/收藏内容、互动内容、品牌偏好、产品偏好社会特征:婚姻状况、家庭情况、社交/信息渠道偏好消费特征:收入状况、购买力水平、已购商品、购买渠道偏好、最后购买时间、购买频次最后介绍一下构建各类标签的优先级。对此需要综合考虑业务需求、构建难易程度等,业务需求各有不同,这里介绍的优先级排序方法主要依据构建的难易程度和各类标签的依存关系,优先级如图10-5所示。
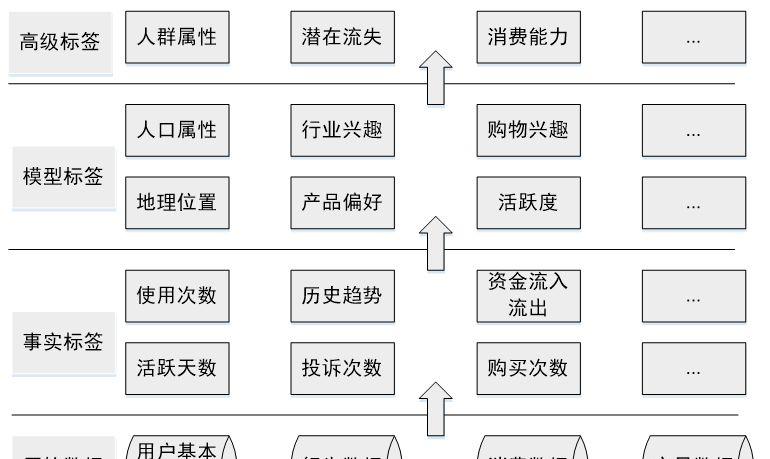 ▲图10-5 各类标签的构建优先级1)事实标签基于原始数据首先构建的是事实标签,事实标签可以从数据库直接获取(如注册信息),或通过简单的统计得到。这类标签构建难度低、实际含义明确,且部分标签可用作后续标签挖掘的基础特征(如产品购买次数可用来作为用户购物偏好的输入特征数据)。事实标签的构造过程,也是对数据加深理解的过程。对数据进行统计的同时,不仅完成了数据的处理与加工,也对数据的分布有了一定的了解,为高级标签的构造做好了准备。2)模型标签模型标签是标签体系的核心,也是用户画像中工作量最大的部分,大多数用户标签的核心都是模型标签。模型标签的构建大多需要用到机器学习和自然语言处理技术,下文介绍的标签构建主要指的是模型标签构建,具体的构造算法会在下文中详细介绍。3)高级标签最后构造的是高级标签,高级标签是基于事实标签和模型标签进行统计建模得出的,它的构造多与实际的业务指标紧密联系。只有完成基础标签的构建,才能够构造高级标签。构建高级标签使用的模型,可以是简单的数据统计模型,也可以是复杂的机器学习模型。03 构建用户画像我们把标签分为三类,这三类标签有较大的差异,构建时所用技术的差别也很大。第一类是人口属性,这一类标签比较稳定,一旦建立很长一段时间基本不用更新,标签体系也比较固定;第二类是兴趣属性,这类标签随时间变化很快,标签有很强的时效性,标签体系也不固定;第三类是地理属性,这一类标签的时效性跨度很大,如GPS轨迹标签需要做到实时更新,而常住地标签一般可以几个月不用更新,所用的挖掘方法和前面两类也大有不同,如图10-6所示。
▲图10-5 各类标签的构建优先级1)事实标签基于原始数据首先构建的是事实标签,事实标签可以从数据库直接获取(如注册信息),或通过简单的统计得到。这类标签构建难度低、实际含义明确,且部分标签可用作后续标签挖掘的基础特征(如产品购买次数可用来作为用户购物偏好的输入特征数据)。事实标签的构造过程,也是对数据加深理解的过程。对数据进行统计的同时,不仅完成了数据的处理与加工,也对数据的分布有了一定的了解,为高级标签的构造做好了准备。2)模型标签模型标签是标签体系的核心,也是用户画像中工作量最大的部分,大多数用户标签的核心都是模型标签。模型标签的构建大多需要用到机器学习和自然语言处理技术,下文介绍的标签构建主要指的是模型标签构建,具体的构造算法会在下文中详细介绍。3)高级标签最后构造的是高级标签,高级标签是基于事实标签和模型标签进行统计建模得出的,它的构造多与实际的业务指标紧密联系。只有完成基础标签的构建,才能够构造高级标签。构建高级标签使用的模型,可以是简单的数据统计模型,也可以是复杂的机器学习模型。03 构建用户画像我们把标签分为三类,这三类标签有较大的差异,构建时所用技术的差别也很大。第一类是人口属性,这一类标签比较稳定,一旦建立很长一段时间基本不用更新,标签体系也比较固定;第二类是兴趣属性,这类标签随时间变化很快,标签有很强的时效性,标签体系也不固定;第三类是地理属性,这一类标签的时效性跨度很大,如GPS轨迹标签需要做到实时更新,而常住地标签一般可以几个月不用更新,所用的挖掘方法和前面两类也大有不同,如图10-6所示。
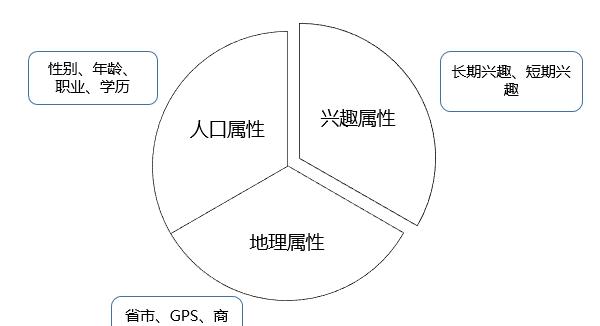 ▲图10-6 三类标签属性1. 人口属性画像人口属性包括年龄、性别、学历、人生阶段、收入水平、消费水平、所属行业等。这些标签基本是稳定的,构建一次可以很长一段时间不用更新,标签的有效期都在一个月以上。同时标签体系的划分也比较固定,表10-2是中国无线营销联盟对人口属性的一个划分。大部分主流的人口属性标签都和这个体系类似,有些在分段上有一些区别。▼表10-2 人口标签
▲图10-6 三类标签属性1. 人口属性画像人口属性包括年龄、性别、学历、人生阶段、收入水平、消费水平、所属行业等。这些标签基本是稳定的,构建一次可以很长一段时间不用更新,标签的有效期都在一个月以上。同时标签体系的划分也比较固定,表10-2是中国无线营销联盟对人口属性的一个划分。大部分主流的人口属性标签都和这个体系类似,有些在分段上有一些区别。▼表10-2 人口标签
 下面来构建特征。通过分析发现男性和女性对于影片的偏好是有差别的,因此使用用户观看的影片列表预测用户性别有一定的可行性。此外,还可以考虑用户的观看时间、浏览器、观看时长等,为了简化,这里只使用用户观看的影片特征。由于观看影片特征是稀疏特征,所以可以调用MLlib,使用LR、线性SVM等模型进行训练。考虑到注册用户填写的用户信息的准确性不高,所以可以从30%的样本集中提取准确性较高的部分(如用户信息填写较完备的)用于训练,因此整体的训练流程如图10-7所示。对于预测性别这样的二分类模型,如果行为的区分度较好,一般准确率和覆盖率都可以达到70%左右。
下面来构建特征。通过分析发现男性和女性对于影片的偏好是有差别的,因此使用用户观看的影片列表预测用户性别有一定的可行性。此外,还可以考虑用户的观看时间、浏览器、观看时长等,为了简化,这里只使用用户观看的影片特征。由于观看影片特征是稀疏特征,所以可以调用MLlib,使用LR、线性SVM等模型进行训练。考虑到注册用户填写的用户信息的准确性不高,所以可以从30%的样本集中提取准确性较高的部分(如用户信息填写较完备的)用于训练,因此整体的训练流程如图10-7所示。对于预测性别这样的二分类模型,如果行为的区分度较好,一般准确率和覆盖率都可以达到70%左右。
 ▲图10-8 三级类目体系1)内容建模新闻数据本身是非结构化的,首先需要人工构建一个层次化的标签体系。考虑如图10-9所示的一篇新闻,看看哪些内容可以表示用户的兴趣。
▲图10-8 三级类目体系1)内容建模新闻数据本身是非结构化的,首先需要人工构建一个层次化的标签体系。考虑如图10-9所示的一篇新闻,看看哪些内容可以表示用户的兴趣。
 ▲图10-9 新闻例子首先,这是一篇体育新闻,体育这个新闻分类可以表示用户兴趣,但是这个标签太粗了,因为用户可能只对足球感兴趣,所以体育这个标签就显得不够准确。其次,可以使用新闻中的关键词,尤其是里面的专有名词(人名、机构名),如“桑切斯”“阿森纳”“厄齐尔”,这些词也表示了用户的兴趣。关键词的主要问题在于粒度太细,如果某天的新闻里没有这些关键词,就无法给用户推荐内容。最后,我们希望有一个中间粒度的标签,既有一定的准确度,又有一定的泛化能力。于是我们尝试对关键词进行聚类,把一类关键词当成一个标签,或者拆分一个分类下的新闻,生成像“足球”这种粒度介于关键词和分类之间的主题标签。我们可以使用文本主题聚类完成主题标签的构建。至此,就完成了对新闻内容从粗到细的“分类-主题-关键词”三层标签体系的内容建模,新闻的三层标签如表10-4所示。▼表10-4 三层标签体系
▲图10-9 新闻例子首先,这是一篇体育新闻,体育这个新闻分类可以表示用户兴趣,但是这个标签太粗了,因为用户可能只对足球感兴趣,所以体育这个标签就显得不够准确。其次,可以使用新闻中的关键词,尤其是里面的专有名词(人名、机构名),如“桑切斯”“阿森纳”“厄齐尔”,这些词也表示了用户的兴趣。关键词的主要问题在于粒度太细,如果某天的新闻里没有这些关键词,就无法给用户推荐内容。最后,我们希望有一个中间粒度的标签,既有一定的准确度,又有一定的泛化能力。于是我们尝试对关键词进行聚类,把一类关键词当成一个标签,或者拆分一个分类下的新闻,生成像“足球”这种粒度介于关键词和分类之间的主题标签。我们可以使用文本主题聚类完成主题标签的构建。至此,就完成了对新闻内容从粗到细的“分类-主题-关键词”三层标签体系的内容建模,新闻的三层标签如表10-4所示。▼表10-4 三层标签体系
 划重点??干货直达??
划重点??干货直达??
终于有人把数据安全讲明白了
35岁的程序员,真的要转管理吗?
数据中台、标签、数据资产相关的15个名词解释
图灵奖得主都写过哪些书?









