哈喽,大家好,我是黎杜,这一期我又来分享自己的干货了,后面的文章的连载主要都是关于Mysql的方面,也是一步一步的由浅到深去学习Mysql,从理论到实战。
上面的思维导图是我总结好几天的Mysql的技术点,有理论也有自己经历的调优的一些实战场景,基本在工作中用到的技术点上面的思维导图都有提及。
首先,这篇算是开篇,先从总体来看Mysql技术点的全貌,分享个人学习Mysql的经验,也会有一些自己涉及到的场景,具体详细的技术点,后面会一点一点的输出。
Mysql安装
首先是安装Mysql,对于Mysql的安装,这里不做过多的详解,可以参考这一篇文章:Mysql 8安装
Mysql基础
假如,你是大学生或者刚学习Mysql入门的话,这一节你可以参考学习,如果你是已经有Mysql技术功底的,这一节可以跳过,直接看后面的进阶部分:

首先,Mysql的基础,主要包含以下几个方面:
(1)Mysql语法基础
语法基础包括创建数据库,删除数据库,查询数据库,表结构的增删改查、数据行的增删改查(select、update、delete、insert的基础语法):
DDL—数据定义语言(Data Define Language):create(创建表),alter(修改表),drop(删除表),truncate(删除表记录),rename(修改表名);DML—数据操纵语言(Data Manipulation Language):select(查),delete(删),update(更新),insert(增);DCL—数据控制语言(Data Control Language):grant(赋予权限),revoke(回收权限);
(2)Mysql查询
Mysql的查询也是最重要的,应该说没有之一,在如今的互联网时代,几乎都是读多写少的场景,所以很大程度上我们学习Mysql,基本的经历都是花在Mysql的查询方面。
Mysql的查询主要包括以下几个方面:
简单查询子查询关联查询左关联(left join)右关联(right join)内关联 (inner ioin)联合查询(union)
看起来Mysql的查询还是挺多的,不过归根结底,都是简单查询堆叠起来的,下面放一个简单查询的全语句,方便大家写sql的时候,可以借鉴:
selectcol1,col2from表1,表2where条件表达式groupby分组having分组条件orderby列名limitnum;
学习后,只有实践才能巩固自己的知识点,百度有很Mysql查询的练习题:
(3)查询原理
上面的查询理论基础学完后,如果觉得有兴趣,可以深入的去了解查询的原理,比如简单查询,select、from、where、group by、having、order by、limit num先后的执行顺序是怎么样的。
假如涉及到查询语句的排序order by,并且order by后面的条件没有加索引和和加了索引执行流程又是怎么样的?其中涉及到的知识点有:全字段和排序rowid排序、内存排序、辅助文件排序,还有sql调优对于排序字段使用explain关键字查看时,出现using filesort,又怎么来调优?这些原理可以参考《Mysql 45讲》的第16讲。

对于复杂查询的话,可以分别弄懂left join、right join、inner join的查询原理,这里放一张这三个join的原理图,详细的可以我们后面的文章进行深入的学习:
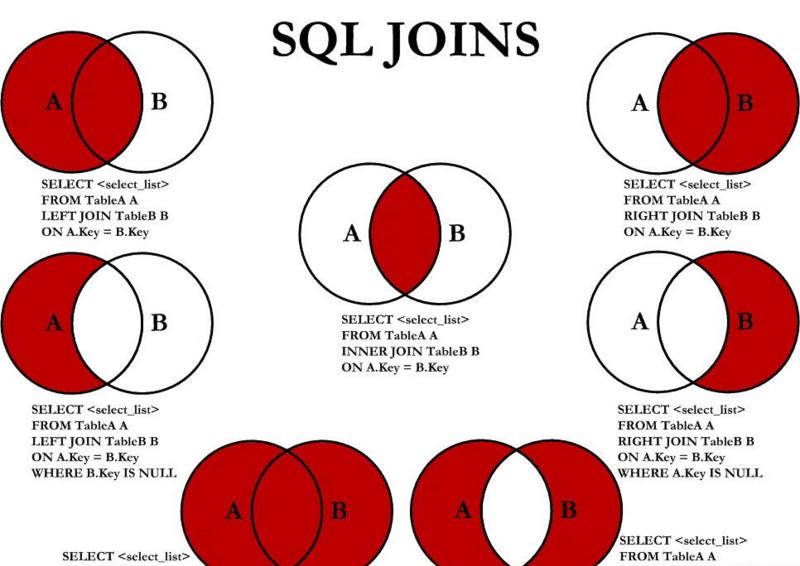 left join(左联接):返回包括左表中的所有记录和右表中联结字段相等的记录。right join(右联接):返回包括右表中的所有记录和左表中联接字段相等的记录。inner join(等值连接):只返回两个表中联接字段相等的行。
left join(左联接):返回包括左表中的所有记录和右表中联结字段相等的记录。right join(右联接):返回包括右表中的所有记录和左表中联接字段相等的记录。inner join(等值连接):只返回两个表中联接字段相等的行。
对于这个原理建议有基础的可以去深入的学习,因为对于你去优化sql的时候,理解非常有帮助。
(4)视图
然后,就是视图部分,视图类似于一些企业的面试,也会问你:
什么是视图?为什么要用视图?
 如何创建视图?(create view 视图名 as select 字段名 from 表名)
如何创建视图?(create view 视图名 as select 字段名 from 表名)
带着这几个问题去学习,基本就没啥问题。这里的视图并不是MVCC的一致性视图。
(5)常用的函数
最后基础部分部分就是函数,常用的函数主要分为以下三类:
时间函数curdate:获取当前日期curtime:获取当前时间now:now()获取当前时间和时间week:week(date)返回日期date为一年的第几周year:year(date)返回日期date的年份hour:hour(time)返回时间time的小时值minute:minute(time)返回时间time的分钟值字符串处理函数:trim:返回字符串s删除了两边空格之后的字符串rtrim:后者返回字符串s,其右边所有空格被删除concat:连接字符串char_length:计算字符串字符个数lower:将str中的字母全部转换成小写数学函数:sum:返回特定列的和;忽略特定列为NULL的行;min:返回特定列的最小值;忽略特定列为NULL的行;max:max函数返回特定列值的最大值;忽略特定列为NULL的行;count:count函数用于计算行数,其中count(*)计算所有行的数目,count(“column”)会忽略column为NULL的行数;avg:计算出平均值(特定列值之和/行数=平均值);使用时注意其会忽略列值为NULL的行;ceil:ceil(x)返回大于或等于数值x的最小整数floor:floor(x)返回小于或等于数值x的最大整数rand:rand()返回0~1 的随机数
这里并没有列举全部的函数,只是大概凭影响列举了一些常用的函数,后买你汇总整理一份全面的函数文章篇,便于使用的时候直接查询,这部分都是死的,也不用全部记,用到什么就是查,把常用的记住就行了。
这些函数的用法就是一个是在select后面的列使用,比如select avg(col) from ……,还有就是可以在having后面也可以使用函数,比如:select ……..having sum(area)>1000000;
对于基础部分,之前我也写过一篇详细的文章,有兴趣的可以看一看:万字长文,最硬核的mysql知识总结
索引
学完上面的基础,我个人是建议学索引,因为索引是优化查询的手段,刚学完上面的基础查询,可以趁热打铁学习索引,连贯性比较强,学习索引个人的建议主要从以下几个方面进行学习:
 索引的概念、底层原理(B 数)创建/删除索引索引的种类、每种索引的创建、适用的场景。索引优化explain关键字,每个字段的含义。索引优化原则索引中重要的概念(索引下推、前缀索引、索引的覆盖)
索引的概念、底层原理(B 数)创建/删除索引索引的种类、每种索引的创建、适用的场景。索引优化explain关键字,每个字段的含义。索引优化原则索引中重要的概念(索引下推、前缀索引、索引的覆盖)
把上面的问题搞清楚了,索引部分也可以算是精通了,其中最重要的就是索引的优化原则,优化是个人实战的经验的总结,理论总是为实践服务的,所以我把索引优化的思维导图单独贴出来:

优化原则的总结基本都在这幅图里面了,熟练的运用这些原则,你就会成为索引优化的高手,比如我们举个实际的场景,之前在一些技术群里面,有技术的盆友说他们同事,写了如下的sql:
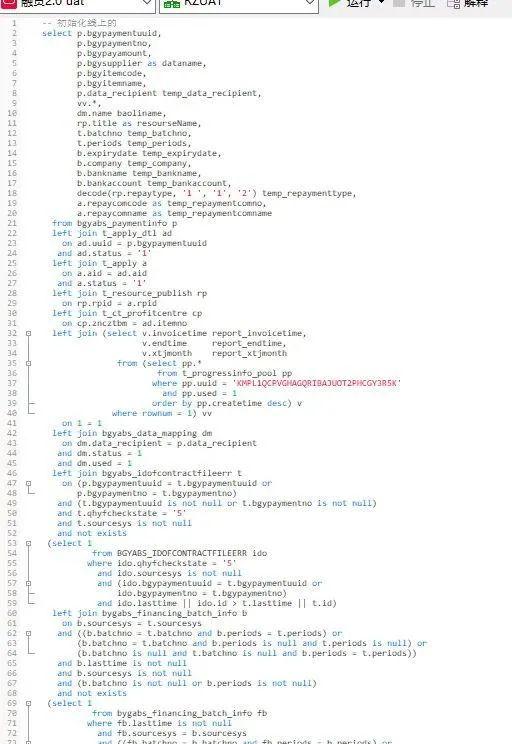
这sql给你一看,你心里肯定是一万个XX马飞过,更不幸的是写这个sql的人走了,然后由于数据量越来越大,后面出现3-5秒才能查出来,此时慢sql就来了,老板就找你叫你优化这个sql。
是不是感觉特别奔溃,其实在一些传统公司,这样的sql随处可见,基本都是sql服务于业务。
然后,开发人员基本不会sql优化手段或者说基本没有优化的意识以及也不了解业务优化手段,都是一句sql走天下。
要是你的同事,你不想打死他才怪,所以遇到这样的长sql,想要优化基本都是遵循一个原则:拆:
从里层往外层拆,子查询可以单独拆为一个查询,一个查询分为多个查询。条件往里层移动,里层能刷选尽量里层刷选,减少join的关联数。关联条件建立索引、查询条件建立索引、order by、group by字段建立索引,能使用索引覆盖尽量使用索引覆盖。
嗯,基本就是遵循上面的原则进行优化,一条sql越复杂,命中索引的概率就越低,然后是结合explain关键字进行优化。
事务
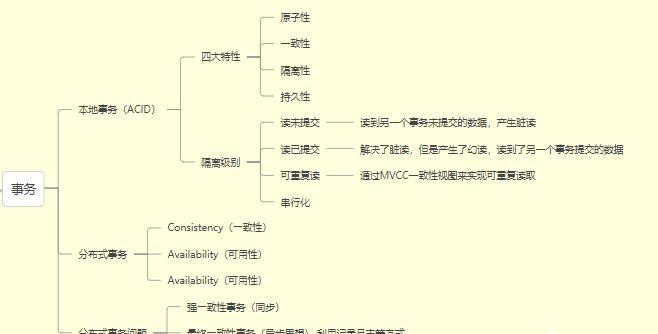
对于Mysql是事务的学习,主要是以下几个方面:
事务的四大特性ACID原子性:同一个事务中,所用的操作都是原子性的,要么都成功,要么都失败。一致性:事务开始后,数据与预期的是一致的,不会出现脏数据的现象。持久性:事务最后修改的数据能够持久化到磁盘中。隔离性:每个事务都是独立的,相互之间不影响。事务隔离级别读未提交:读取到被人未提交的事务读提交:读取到别人提交的事务可重复读:同一个事务中,事务的开始与事务结束之前读取的数据都是一致的。串行化:事务的执行是串行的。事务问题脏读:读到别的事务还没提交的数据不可重复读:主要是针对修改,一个事务读取的数据行被另一个事务修改,当前事务再次读取的时候与上一次读取的数据不一致。幻读:主要是针对新插入的数据,开始读取到另一个事务新插入的数据行。一致性视图MVCC原理当前读快照读
除了学习上面的事务的理论之外,可以自己开多个session(窗口),然后使用begin/commit来手动的开启和提交事务,进行测试事务的特性,特别是脏读、不可重复读、幻读的问题,可以自己手动测一测。
对于事务,在《Mysql 45讲》的第3讲以及第8讲讲的非常的清楚,大家可以参考参考:
对于事务的详细介绍,我之前也写过一篇原创,大家可以参考参考:我以为我对Mysql事务很熟,直到我遇到了阿里面试官
锁机制
然后,接下来要学的就是锁机制,锁机制与事务之间的关系非常的紧密,测试的方法也是非常类似,所以建议事务与锁机制一起学,在《Mysql 45讲》中锁机制和事务也是放在相邻的位置:
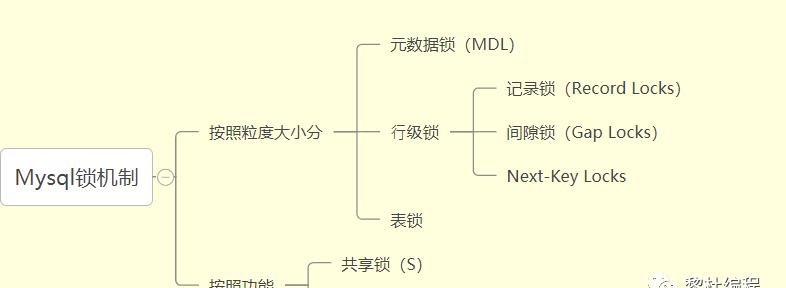
锁机制中主要是搞懂按照不同粒度进行划分的锁的种类有哪些,以及每种锁的概念,自己怎么测试复现。
锁机制是出现在InnoDB引擎中,也可以对比Myisam的区别,为啥InnoDB会出现锁机制,锁机制又是怎么保证并发的、数据库里面的数据一致性的。
对于锁机制和事务,我之前也写过一篇详细的文章,不过是偏向于面试的,大家也可参考参考:大厂面试官必问的Mysql锁机制
日志
Mysql的日志篇主要是三大日志redo log、binlog、undo log:
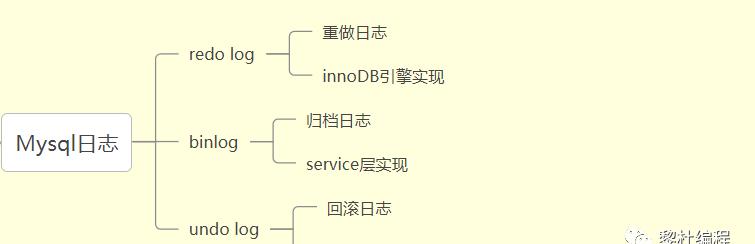
主要学习的知识点如下:
三大日志的概念,作用分别是什么?binlog和redo log是怎么保证数据一致性?两阶段提交又是怎么回事?为什么需要两阶段提交?为什么有了binlog又出现redo log?在保证事务的可重复读的隔离级别下,MVCC又是怎么运用undo log日志的?
这里也是推荐《Mysql 45讲》,在第二讲和第15讲也是比较详细的讲解了redo log和binlog的作用,undo log是MVCC的内容,在讲解事务的隔离级别也是有讲解undo log的,所以大家可以详细参考文章里面的知识点
 存储引擎
存储引擎
存储引擎部分我推荐学习InnoDB和Myisam,其他的存储引擎不用学,若是你是DBA,那其他类型的存储引擎可能也要学,作为开发学习这两款就够了。
学习InnoDB和Myisam,主要学习的内容如下:
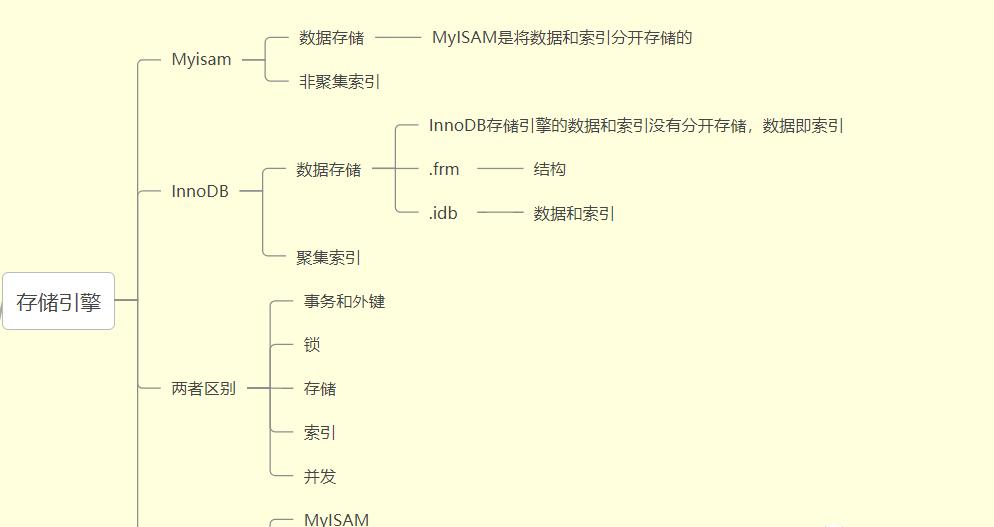
总的来说就是以下几点:
InnoDB和Myisam区别是什么?用的索引模型,索引存储,聚族索引和非聚族索引区别、InnoDB和Myisam主键索引和二级索引叶子节点的存储区别。InnoDB和Myisam存储上的区别。InnoDB和Myisam并发度的支持上的区别。在事务和外键支持上,InnoDB和Myisam的区别。InnoDB和Myisam使用的场景,哪一个适用于读多写少哪一个适用于读少写多?
基本上就是这些内容,其中使用的场景和聚族索引和非聚族索引、事务的支持度是重点。
Mysql调优
上的知识点基本都是和理论相关的,下面的开始就比较偏向于实战部分,Mysql的调优的其中一部分,上面已经提交到了,就是索引的优化原则,这部分可以说是学习Mysql的最终目的之一,也是最重要的一点之一:

除了上面索引的优化,Mysql的调优,还包括Mysql连接池的设置,连接数的设置、以及Mysql死锁的排查和解决、Mysql主从模式、分库分表等内容:

上面的是都实现Mysql高可用和高性能的基础,所以对于这一块的内容,可能更多的经验是实践得来的,比如我们之前的一个项目,上线前进行压测,发现并发度不行,性能瓶颈分析是数据库的连接池设置有问题(默认是20,修改为300)。
再比如慢SQL的分析,再基于公司监控平台的基础上,对慢sql进行优化,首先考虑加索引,若是索引都不能解决看是否是由于sql太大导致的,那就按照上面讲的进行sql的拆分,分开查询。
若是数据量实在太大,就会考虑分库分表进行优化,这些都是再实际的工作中得来的经验,也不断的再工作中得到验证。
还有就是优化业务,作为一个高级的程序员,首先你得对业务非常的熟悉,若是有一个需求是要查询主表和从表两个表中的一个字段为updateTime的罪最新时间。
假如你不优化业务,你可能首先要娶取出从表的最新时间(这个最新时间可能没有,因为主表对应从表没有数据),然后拿这个最新实践还要和主表的updateTime进行比较最新时间,那么这里的sql涉及到的函数就比较多。
对于Mysql服务器来说是非常消耗性能的,但是你有优化业务的能力,再主表新增一个实践作为最新的时间,对于写入和新增从表的数据以及写入和更新主表数据时,每次去更新那个时间,保持这个时间为最新的时间,那么你就不用再去连接从表并进行复杂大量的计算。
这样的原理原理就是牺牲写的性能(每次更新的时候都要去维护这个最新时间),来提高查询的性能。
还有一些场景比如PC端难免会有一些数据大屏、数据面板的展示,对于数据量百万级别以上,使用Mysql的计算能力去计算的,会是非常的慢,所以导致大屏查询性能慢,一般大屏都是非常重要的,位于首页,怎么可能让他性能差呢。
所以,对于这种有时候没办法使用索引来解决的时候,你就要考虑数据的预先计算,缓存储存,可以另外涉及一个表,或者存于缓存中,每次写数据的时候,更新这个结果数据,查询的时候,直接获取就行了,就不用再次进行计算。
ok,这些都是一些优化的手段,并且是结合实际的开发场景总结的,每一个业务场景都不一样,所以,你也要结合自己的业务场景对自己的业务进行分析优化。
Mysql主从
Mysql的主从也是优化的Mysql的手段之一,主要是为了减轻Mysql的负担,讲读写分离,主库负责写数据,从库负责读数据,并且可能一主多从,从库之间分摊了读的压力:
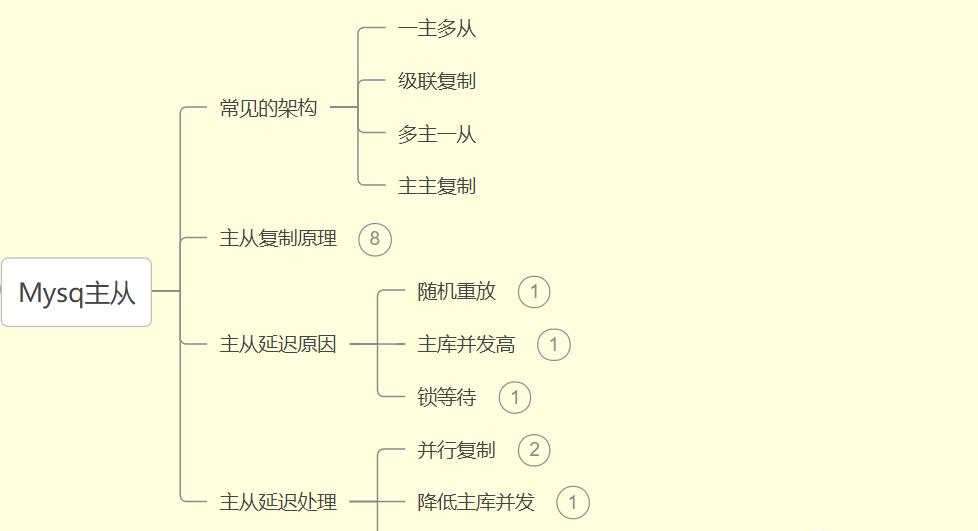
对于Mlsql的主从,首先要搞清楚主从有哪些模式?主从的原理是什么?主从延迟的原因有哪些?以及出现主从延迟该怎么解决?
带着这四个问题去学,不过面试还是实际中都有能力去解决对应的问题,当然可能在实践中还需要大量的场景来锻炼。
分库分表
若是主从模式、索引优化都没办法解决性能瓶颈的问题,可能就要考虑分库分表了:

分库分表是Mysql优化的最后一道关卡,顾名思义包括分库和分表,垂直分和水平分。
那么,分库分表之后就会带来一系列的问题,比如跨库的join非常麻烦,本地事务没办法解决,需要引入分布式事务,以及分布式id的问题,这些又是怎么解决的?原理是什么?
最后,就是进行分库分表可以使用那些中间件mycat、sharding-jdbc,这两个是比较常见的分库分表工具。
分库分表要学习的内容也基本就是这些,当这些基本学完了,你也就精通Mysql了,有人会问,那么多知识点,怎么学怎么记,根本就记不住。
其实根据个人的经验,一个是知识点学习后的总结,我个人习惯是比较喜欢做思维导图的,学习知识是一个螺旋式的过程,并不是一次吃成一个胖子,每次都会把自己以前学过的知识点进行回顾,若是有应用的场景,那么对于有些知识点是记得非常捞的。
所以,不断的回顾,学会总结和概括,应用场景,学会对知识点做减法,慢慢的就会融汇贯通,而且我个人有一种经验就是,你每一个层次:初级=>中级=>高级去看一个知识点都有可能得到不同的感悟和心得体会。
面试题
最后的就是Mysql的面试题,其实网上也是挺多的,我这里也只列举了这么几个:
前面我也写过一篇专门是Mysql的面试的文章,总共有20道面试题,有兴趣可以看一看:精心为你准备的最全的20道Mysql面试题。
— EOF —
推荐↓↓↓









