这是一篇入门文章,Hadoop的学习方法很多,网上也有很多学习路线图。本文的思路是:以安装部署Apache Hadoop2.x版本为主线,来介绍Hadoop2.x的架构组成、各模块协同工作原理、技术细节。安装不是目的,通过安装认识Hadoop才是目的。
第一部分:Linux环境安装
第一部分介绍Linux环境的安装、配置、Java JDK安装等。
第二部分:Hadoop本地模式安装
Hadoop本地模式只是用于本地开发调试,或者快速安装体验Hadoop,这部分做简单的介绍。
第三部分:Hadoop伪分布式模式安装
伪分布式的意思是虽然各个模块是在各个进程上分开运行的,但是只是运行在一个操作系统上的,并不是真正的分布式。
第四部分:完全分布式安装
完全分布式模式才是生产环境采用的模式,Hadoop运行在服务器集群上,生产环境一般都会做HA,以实现高可用。
第一部分:Linux环境安装
第三步、安装JDK查看是否已经安装了java JDK。
[root@bigdata-senior01Desktop]#java–version注意:Hadoop机器上的JDK,最好是Oracle的JavaJDK,不然会有一些问题,比如可能没有JPS命令。如果安装了其他版本的JDK,卸载掉。将jdk-7u67-linux-x64.tar.gz解压到/opt/modules目录下[root@bigdata-senior01/]#tar-zxvfjdk-7u67-linux-x64.tar.gz-C/opt/modules#添加环境变量设置JDK的环境变量JAVA_HOME。需要修改配置文件/etc/profile,追加exportJAVA_HOME=”/opt/modules/jdk1.7.0_67″exportPATH=$JAVA_HOME/bin:$PATH#修改完毕后,执行source/etc/profile#安装后再次执行java–version,可以看见已经安装完成。[root@bigdata-senior01/]#java-versionjavaversion”1.7.0_67″Java(TM)SERuntimeEnvironment(build1.7.0_67-b01)JavaHotSpot(TM)64-BitServerVM(build24.65-b04,mixedmode)第二部分:Hadoop本地模式安装
Hadoop部署模式有:本地模式、伪分布模式、完全分布式模式、HA完全分布式模式。区分的依据是NameNode、DataNode、ResourceManager、NodeManager等模块运行在几个JVM进程、几个机器。
模式名称各个模块占用的JVM进程数各个模块运行在几个机器数上本地模式1个1个伪分布式模式N个1个完全分布式模式N个N个HA完全分布式N个N个
本地模式部署本地模式是最简单的模式,所有模块都运行与一个JVM进程中,使用的本地文件系统,而不是HDFS,本地模式主要是用于本地开发过程中的运行调试用。默认的就是本地模式。创建一个存放本地模式hadoop的目录。
[hadoop@bigdata-senior01modules]$mkdir/opt/modules/hadoopstandalone#解压hadoop文件[hadoop@bigdata-senior01modules]$tar-zxf/opt/sofeware/hadoop-2.5.0.tar.gz-C/opt/modules/hadoopstandalone/#确保JAVA_HOME环境变量已经配置好[hadoop@bigdata-senior01modules]$echo${JAVA_HOME}/opt/modules/jdk1.7.0_67
运行MapReduce程序,验证,我们这里用hadoop自带的wordcount例子来在本地模式下测试跑mapreduce。
#准备mapreduce输入文件wc.input[hadoop@bigdata-senior01modules]$cat/opt/data/wc.inputhadoopmapreducehivehbasesparkstormsqoophadoophivesparkhadoop#运行hadoop自带的mapreduceDemo[hadoop@bigdata-senior01hadoopstandalone]$bin/hadoopjarshare/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jarwordcount/opt/data/wc.inputoutput2#这里可以看到jobID中有local字样,说明是运行在本地模式下的。
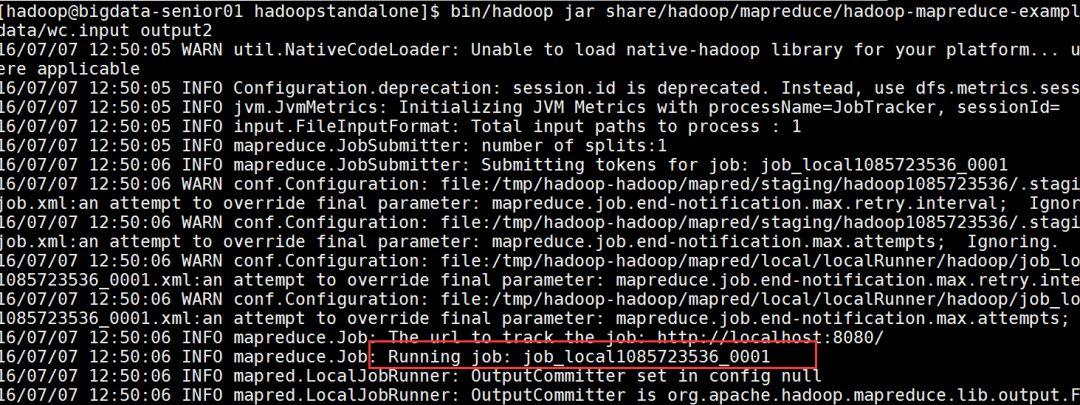
#查看输出文件,本地模式下,mapreduce的输出是输出到本地。[hadoop@bigdata-senior01hadoopstandalone]$lloutput2total4-rw-r–r–1hadoophadoop60Jul712:50part-r-00000-rw-r–r–1hadoophadoop0Jul712:50_SUCCESS#输出目录中有_SUCCESS文件说明JOB运行成功,part-r-00000是输出结果文件。第三部分:Hadoop伪分布式模式安装
伪分布式Hadoop部署过程
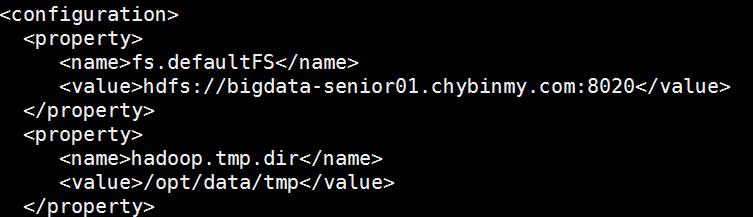
Hadoop所用的用户设置#创建一个名字为hadoop的普通用户[root@bigdata-senior01~]#useraddhadoop[root@bigdata-senior01~]#passwdhadoop#给hadoop用户sudo权限[root@bigdata-senior01~]#vim/etc/sudoers#设置权限,学习环境可以将hadoop用户的权限设置的大一些,但是生产环境一定要注意普通用户的权限限制。rootALL=(ALL)ALLhadoopALL=(root)NOPASSWD:ALL#注意:如果root用户无权修改sudoers文件,先手动为root用户添加写权限。[root@bigdata-senior01~]#chmodu w/etc/sudoers#切换到hadoop用户[root@bigdata-senior01~]#su-hadoop[hadoop@bigdata-senior01~]$创建存放hadoop文件的目录[hadoop@bigdata-senior01~]$sudomkdir/opt/modules#将hadoop文件夹的所有者指定为hadoop用户,如果存放hadoop的目录的所有者不是hadoop,之后hadoop运行中可能会有权限问题,那么就讲所有者改为hadoop。[hadoop@bigdata-senior01~]#sudochown-Rhadoop:hadoop/opt/modules解压Hadoop目录文件#复制hadoop-2.5.0.tar.gz到/opt/modules目录下。解压hadoop-2.5.0.tar.gz。[hadoop@bigdata-senior01~]#cd/opt/modules[hadoop@bigdata-senior01hadoop]#tar-zxvfhadoop-2.5.0.tar.gz配置Hadoop#配置Hadoop环境变量[hadoop@bigdata-senior01hadoop]#vim/etc/profile#追加配置:exportHADOOP_HOME=”/opt/modules/hadoop-2.5.0″exportPATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH#执行:source/etc/profile使得配置生效#验证HADOOP_HOME参数:[hadoop@bigdata-senior01/]$echo$HADOOP_HOME/opt/modules/hadoop-2.5.0#配置hadoop-env.sh、mapred-env.sh、yarn-env.sh文件的JAVA_HOME参数[hadoop@bigdata-senior01~]$sudovim${HADOOP_HOME}/etc/hadoop/hadoop-env.sh#修改JAVA_HOME参数为:exportJAVA_HOME=”/opt/modules/jdk1.7.0_67″配置core-site.xml
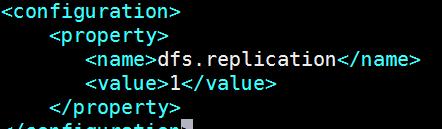
[hadoop@bigdata-senior01hadoop-2.5.0]$vim${HADOOP_HOME}/etc/hadoop/hdfs-site.xm<property><name>dfs.replication</name><value>1</value></property>#dfs.replication配置的是HDFS存储时的备份数量,因为这里是伪分布式环境只有一个节点,所以这里设置为1。格式化HDFS。
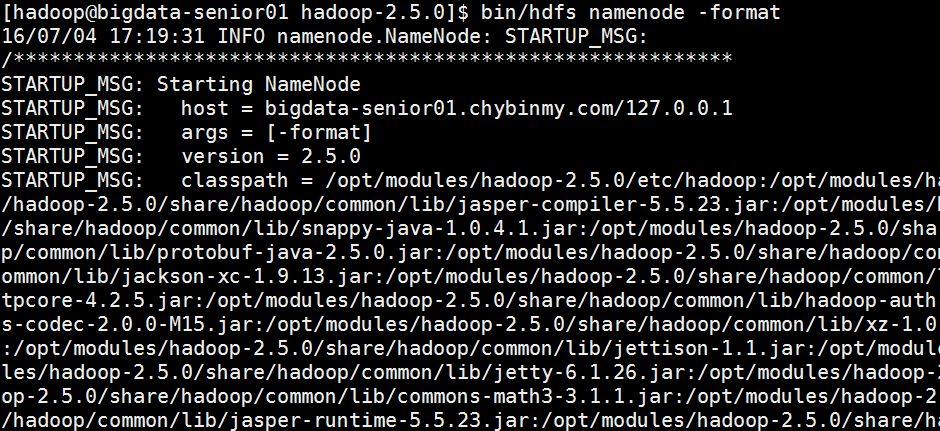
[hadoop@bigdata-senior01~]$hdfsnamenode–format#格式化是对HDFS这个分布式文件系统中的DataNode进行分块,统计所有分块后的初始元数据的存储在NameNode中。格式化后,查看core-site.xml里hadoop.tmp.dir(本例是/opt/data目录)指定的目录下是否有了dfs目录,如果有,说明格式化成功。注意:格式化时,这里注意hadoop.tmp.dir目录的权限问题,应该hadoop普通用户有读写权限才行,可以将/opt/data的所有者改为hadoop。[hadoop@bigdata-senior01hadoop-2.5.0]$sudochown-Rhadoop:hadoop/opt/data#查看NameNode格式化后的目录。[hadoop@bigdata-senior01~]$ll/opt/data/tmp/dfs/name/current

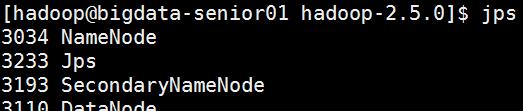
fsimage是NameNode元数据在内存满了后,持久化保存到的文件。fsimage*.md5是校验文件,用于校验fsimage的完整性。seen_txid是hadoop的版本vession文件里保存:namespaceID:NameNode的唯一ID。clusterID:集群ID,NameNode和DataNode的集群ID应该一致,表明是一个集群。#MonJul0417:25:50CST2016namespaceID=2101579007clusterID=CID-205277e6-493b-4601-8e33-c09d1d23ece4cTime=0storageType=NAME_NODEblockpoolID=BP-1641019026-127.0.0.1-1467624350057layoutVersion=-57启动NameNode[hadoop@bigdata-senior01hadoop-2.5.0]$${HADOOP_HOME}/sbin/hadoop-daemon.shstartnamenodestartingnamenode,loggingto/opt/modules/hadoop-2.5.0/logs/hadoop-hadoop-namenode-bigdata-senior01.chybinmy.com.out启动DataNode[hadoop@bigdata-senior01hadoop-2.5.0]$${HADOOP_HOME}/sbin/hadoop-daemon.shstartdatanodestartingdatanode,loggingto/opt/modules/hadoop-2.5.0/logs/hadoop-hadoop-datanode-bigdata-senior01.chybinmy.com.out启动SecondaryNameNode[hadoop@bigdata-senior01hadoop-2.5.0]$${HADOOP_HOME}/sbin/hadoop-daemon.shstartsecondarynamenodestartingsecondarynamenode,loggingto/opt/modules/hadoop-2.5.0/logs/hadoop-hadoop-secondarynamenode-bigdata-senior01.chybinmy.com.outJPS命令查看是否已经启动成功,有结果就是启动成功了。[hadoop@bigdata-senior01hadoop-2.5.0]$jps3034NameNode3233Jps3193SecondaryNameNode3110DataNode
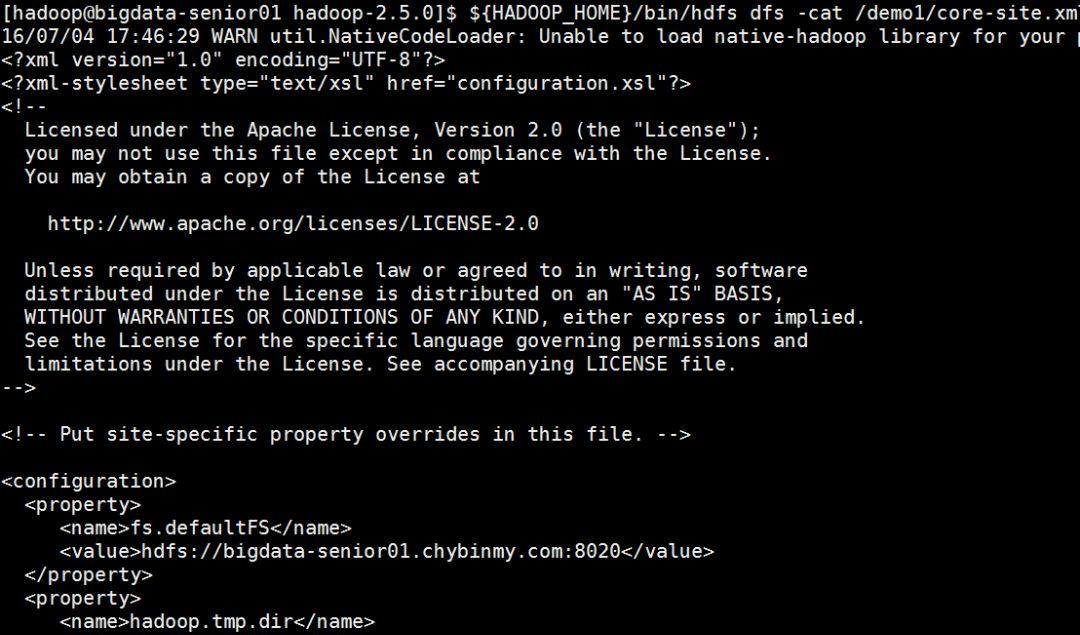
HDFS上测试创建目录、上传、下载文件#HDFS上创建目录[hadoop@bigdata-senior01hadoop-2.5.0]$${HADOOP_HOME}/bin/hdfsdfs-mkdir/demo1上传本地文件到HDFS上[hadoop@bigdata-senior01hadoop-2.5.0]$${HADOOP_HOME}/bin/hdfsdfs-put${HADOOP_HOME}/etc/hadoop/core-site.xml/demo1#读取HDFS上的文件内容[hadoop@bigdata-senior01hadoop-2.5.0]$${HADOOP_HOME}/bin/hdfsdfs-cat/demo1/core-site.xm
#从HDFS上下载文件到本地[hadoop@bigdata-senior01hadoop-2.5.0]$bin/hdfsdfs-get/demo1/core-site.xml
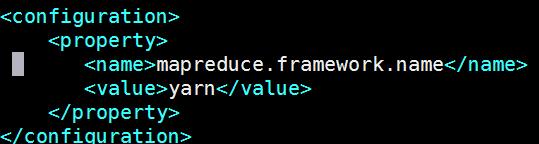
配置、启动YARN#配置mapred-site.xml,默认没有mapred-site.xml文件,但是有个mapred-site.xml.template配置模板文件。复制模板生成mapred-site.xml。[hadoop@bigdata-senior01hadoop-2.5.0]#cpetc/hadoop/mapred-site.xml.templateetc/hadoop/mapred-site.xml#添加配置如下:<property><name>mapreduce.framework.name</name><value>yarn</value></property>#指定mapreduce运行在yarn框架上。
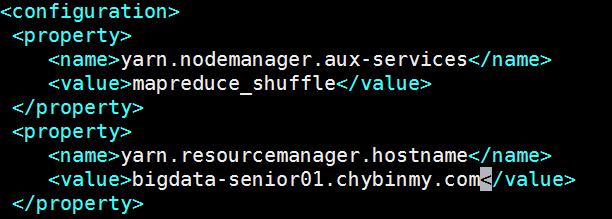
#配置yarn-site.xml添加配置如下:<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name><value>bigdata-senior01.chybinmy.com</value></property>yarn.nodemanager.aux-services配置了yarn的默认混洗方式,选择为mapreduce的默认混洗算法。yarn.resourcemanager.hostname指定了Resourcemanager运行在哪个节点上。
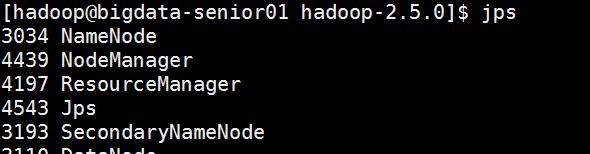
#启动Resourcemanager[hadoop@bigdata-senior01hadoop-2.5.0]$${HADOOP_HOME}/sbin/yarn-daemon.shstartresourcemanager#启动nodemanager[hadoop@bigdata-senior01hadoop-2.5.0]$${HADOOP_HOME}/sbin/yarn-daemon.shstartnodemanager#查看是否启动成功[hadoop@bigdata-senior01hadoop-2.5.0]$jps3034NameNode4439NodeManager4197ResourceManager4543Jps3193SecondaryNameNode3110DataNode
#可以看到ResourceManager、NodeManager已经启动成功了。YARN的Web页面
YARN的Web客户端端口号是8088,通过http://192.168.100.10:8088/可以查看。
运行MapReduce Job#创建测试用的Input文件,创建输入目录:[hadoop@bigdata-senior01hadoop-2.5.0]$bin/hdfsdfs-mkdir-p/wordcountdemo/input#创建原始文件:在本地/opt/data目录创建一个文件wc.input,内容如下。#将wc.input文件上传到HDFS的/wordcountdemo/input目录中:[hadoop@bigdata-senior01hadoop-2.5.0]$bin/hdfsdfs-put/opt/data/wc.input/wordcountdemo/input#运行WordCountMapReduceJob[hadoop@bigdata-senior01hadoop-2.5.0]$bin/yarnjarshare/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jarwordcount/wordcountdemo/input/wordcountdemo/output#查看输出结果目录[hadoop@bigdata-senior01hadoop-2.5.0]$bin/hdfsdfs-ls/wordcountdemo/output-rw-r–r–1hadoopsupergroup02016-07-0505:12/wordcountdemo/output/_SUCCESS-rw-r–r–1hadoopsupergroup602016-07-0505:12/wordcountdemo/output/part-r-00000#output目录中有两个文件,_SUCCESS文件是空文件,有这个文件说明Job执行成功。part-r-00000文件是结果文件,其中-r-说明这个文件是Reduce阶段产生的结果,mapreduce程序执行时,可以没有reduce阶段,但是肯定会有map阶段,如果没有reduce阶段这个地方有是-m-。一个reduce会产生一个part-r-开头的文件。查看输出文件内容。[hadoop@bigdata-senior01hadoop-2.5.0]$bin/hdfsdfs-cat/wordcountdemo/output/part-r-00000hadoop3hbase1hive2mapreduce1spark2sqoop1storm1#结果是按照键值排好序的。停止Hadoop[hadoop@bigdata-senior01hadoop-2.5.0]$sbin/hadoop-daemon.shstopnamenodestoppingnamenode[hadoop@bigdata-senior01hadoop-2.5.0]$sbin/hadoop-daemon.shstopdatanodestoppingdatanode[hadoop@bigdata-senior01hadoop-2.5.0]$sbin/yarn-daemon.shstopresourcemanagerstoppingresourcemanager[hadoop@bigdata-senior01hadoop-2.5.0]$sbin/yarn-daemon.shstopnodemanagerstoppingnodemanager
Hadoop各个功能模块的理解
1、 HDFS模块
HDFS负责大数据的存储,通过将大文件分块后进行分布式存储方式,突破了服务器硬盘大小的限制,解决了单台机器无法存储大文件的问题,HDFS是个相对独立的模块,可以为YARN提供服务,也可以为HBase等其他模块提供服务。
2、 YARN模块
YARN是一个通用的资源协同和任务调度框架,是为了解决Hadoop1.x中MapReduce里NameNode负载太大和其他问题而创建的一个框架。YARN是个通用框架,不止可以运行MapReduce,还可以运行Spark、Storm等其他计算框架。
3、 MapReduce模块
MapReduce是一个计算框架,它给出了一种数据处理的方式,即通过Map阶段、Reduce阶段来分布式地流式处理数据。它只适用于大数据的离线处理,对实时性要求很高的应用不适用。
开启历史服务
[hadoop@bigdata-senior01hadoop-2.5.0]$sbin/mr-jobhistory-daemon.shstarthistoryserver
开启后,可以通过Web页面查看历史服务器:http://bigdata-senior01.chybinmy.com:19888/
Web查看job执行历史运行一个mapreduce任务[hadoop@bigdata-senior01hadoop-2.5.0]$bin/yarnjarshare/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jarwordcount/wordcountdemo/input/wordcountdemo/output1#job执行中
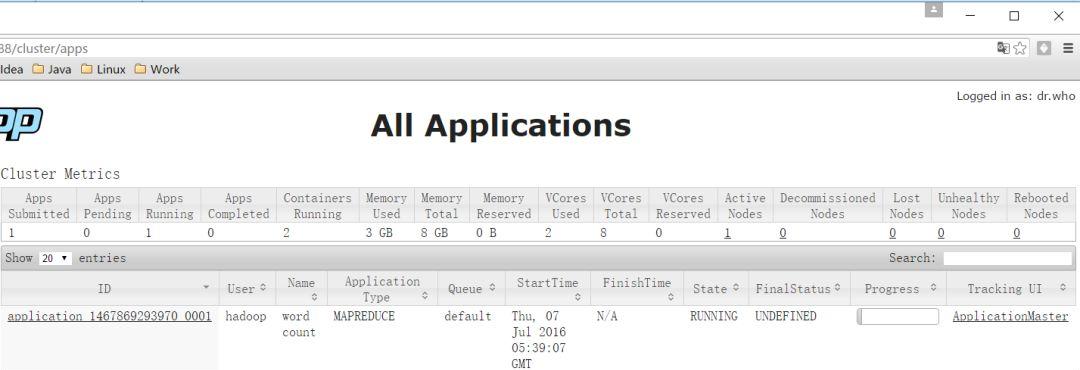
#查看job历史
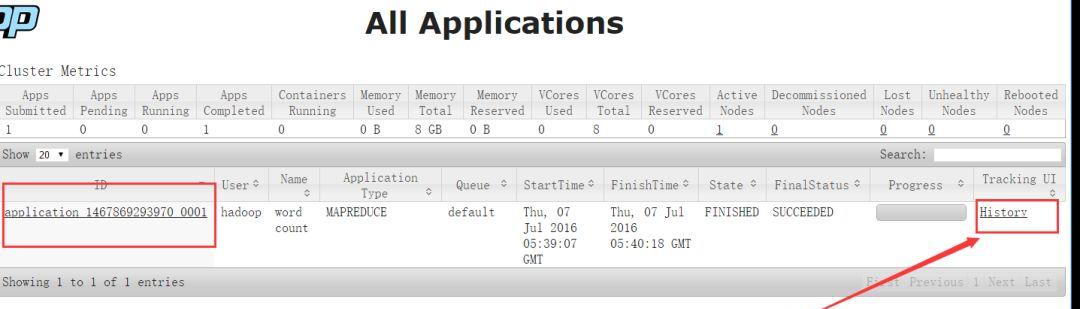
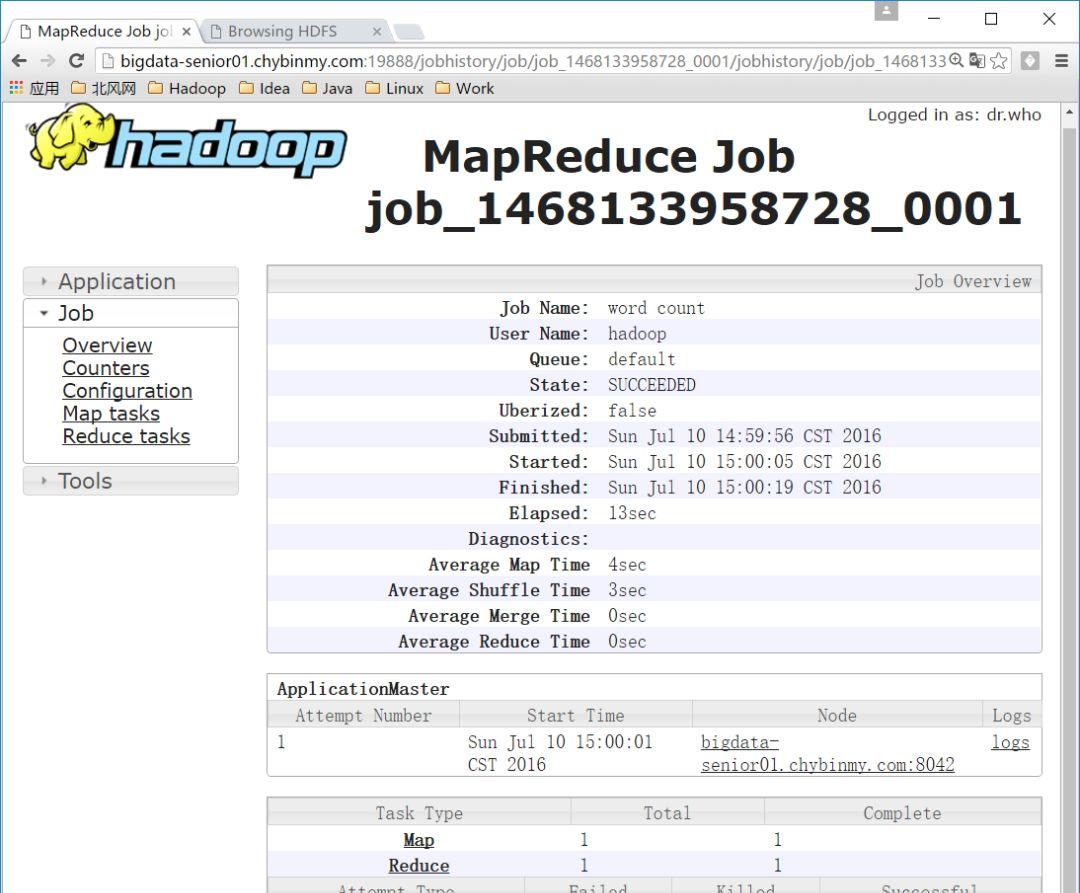
开启日志聚集
日志聚集介绍
MapReduce是在各个机器上运行的,在运行过程中产生的日志存在于各个机器上,为了能够统一查看各个机器的运行日志,将日志集中存放在HDFS上,这个过程就是日志聚集。
开启日志聚集#配置日志聚集功能:Hadoop默认是不启用日志聚集的。在yarn-site.xml文件里配置启用日志聚集。<property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log-aggregation.retain-seconds</name><value>106800</value></property>yarn.log-aggregation-enable:是否启用日志聚集功能。yarn.log-aggregation.retain-seconds:设置日志保留时间,单位是秒。#将配置文件分发到其他节点:[hadoop@bigdata-senior01hadoop]$scp/opt/modules/hadoop-2.5.0/etc/hadoop/yarn-site.xmlbigdata-senior02.chybinmy.com:/opt/modules/hadoop-2.5.0/etc/hadoop/[hadoop@bigdata-senior01hadoop]$scp/opt/modules/hadoop-2.5.0/etc/hadoop/yarn-site.xmlbigdata-senior03.chybinmy.com:/opt/modules/hadoop-2.5.0/etc/hadoop/#重启Yarn进程:[hadoop@bigdata-senior01hadoop-2.5.0]$sbin/stop-yarn.sh[hadoop@bigdata-senior01hadoop-2.5.0]$sbin/start-yarn.sh#重启HistoryServer进程:[hadoop@bigdata-senior01hadoop-2.5.0]$sbin/mr-jobhistory-daemon.shstophistoryserver[hadoop@bigdata-senior01hadoop-2.5.0]$sbin/mr-jobhistory-daemon.shstarthistoryserver#测试日志聚集,运行一个demoMapReduce,使之产生日志:bin/yarnjarshare/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jarwordcount/input/output1#查看日志:运行Job后,就可以在历史服务器Web页面查看各个Map和Reduce的日志了。第四部分:完全分布式安装
完全布式环境部署Hadoop完全分部式是真正利用多台Linux主机来进行部署Hadoop,对Linux机器集群进行规划,使得Hadoop各个模块分别部署在不同的多台机器上。
服务器功能规划bigdata-senior01.chybinmy.combigdata-senior02.chybinmy.combigdata-senior03.chybinmy.comNameNodeResourceManageDataNodeDataNodeDataNodeNodeManagerNodeManagerNodeManagerHistoryServerSecondaryNameNode在第一台机器上安装新的Hadoop
为了和之前BigData01机器上安装伪分布式Hadoop区分开来,我们将BigData01上的Hadoop服务都停止掉,然后在一个新的目录/opt/modules/app下安装另外一个Hadoop。我们采用先在第一台机器上解压、配置Hadoop,然后再分发到其他两台机器上的方式来安装集群。
Hadoop集群中的各个机器间会相互地通过SSH访问,每次访问都输入密码是不现实的,所以要配置各个机器间的SSH是无密码登录的。
#在BigData01上生成公钥[hadoop@bigdata-senior01hadoop-2.5.0]$ssh-keygen-trsa一路回车,都设置为默认值,然后再当前用户的Home目录下的.ssh目录中会生成公钥文件(id_rsa.pub)和私钥文件(id_rsa)。#分发公钥[hadoop@bigdata-senior01hadoop-2.5.0]$ssh-copy-idbigdata-senior01.chybinmy.com[hadoop@bigdata-senior01hadoop-2.5.0]$ssh-copy-idbigdata-senior02.chybinmy.com[hadoop@bigdata-senior01hadoop-2.5.0]$ssh-copy-idbigdata-senior03.chybinmy.com#设置BigData02、BigData03到其他机器的无密钥登录,同样的在BigData02、BigData03上生成公钥和私钥后,将公钥分发到三台机器上。分发Hadoop文件#首先在其他两台机器上创建存放Hadoop的目录[hadoop@bigdata-senior02~]$mkdir/opt/modules/app[hadoop@bigdata-senior03~]$mkdir/opt/modules/app#通过Scp分发Hadoop根目录下的share/doc目录是存放的hadoop的文档,文件相当大,建议在分发之前将这个目录删除掉,可以节省硬盘空间并能提高分发的速度。doc目录大小有1.6G。[hadoop@bigdata-senior01hadoop-2.5.0]$du-sh/opt/modules/app/hadoop-2.5.0/share/doc1.6G/opt/modules/app/hadoop-2.5.0/share/doc[hadoop@bigdata-senior01hadoop-2.5.0]$scp-r/opt/modules/app/hadoop-2.5.0/bigdata-senior02.chybinmy.com:/opt/modules/app[hadoop@bigdata-senior01hadoop-2.5.0]$scp-r/opt/modules/app/hadoop-2.5.0/bigdata-senior03.chybinmy.com:/opt/modules/app格式NameNode#在NameNode机器上执行格式化:[hadoop@bigdata-senior01hadoop-2.5.0]$/opt/modules/app/hadoop-2.5.0/bin/hdfsnamenode–format注意:如果需要重新格式化NameNode,需要先将原来NameNode和DataNode下的文件全部删除,不然会报错,NameNode和DataNode所在目录是在core-site.xml中hadoop.tmp.dir、dfs.namenode.name.dir、dfs.datanode.data.dir属性配置的。<property><name>hadoop.tmp.dir</name><value>/opt/data/tmp</value></property><property><name>dfs.namenode.name.dir</name><value>file://${hadoop.tmp.dir}/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file://${hadoop.tmp.dir}/dfs/data</value></property>#因为每次格式化,默认是创建一个集群ID,并写入NameNode和DataNode的VERSION文件中(VERSION文件所在目录为dfs/name/current和dfs/data/current),重新格式化时,默认会生成一个新的集群ID,如果不删除原来的目录,会导致namenode中的VERSION文件中是新的集群ID,而DataNode中是旧的集群ID,不一致时会报错。另一种方法是格式化时指定集群ID参数,指定为旧的集群ID。启动集群#启动HDFS[hadoop@bigdata-senior01hadoop-2.5.0]$/opt/modules/app/hadoop-2.5.0/sbin/start-dfs.sh
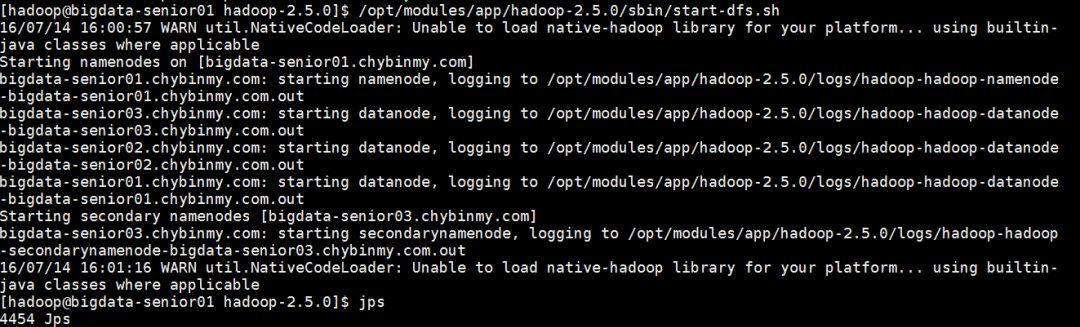
#启动YARN[hadoop@bigdata-senior01hadoop-2.5.0]$/opt/modules/app/hadoop-2.5.0/sbin/start-yarn.sh#在BigData02上启动ResourceManager:[hadoop@bigdata-senior02hadoop-2.5.0]$sbin/yarn-daemon.shstartresourcemanager#启动日志服务器因为我们规划的是在BigData03服务器上运行MapReduce日志服务,所以要在BigData03上启动。[hadoop@bigdata-senior03~]$/opt/modules/app/hadoop-2.5.0/sbin/mr-jobhistory-daemon.shstarthistoryserverstartinghistoryserver,loggingto/opt/modules/app/hadoop-2.5.0/logs/mapred-hadoop-historyserver-bigdata-senior03.chybinmy.com.out[hadoop@bigdata-senior03~]$jps3570Jps3537JobHistoryServer3310SecondaryNameNode3213DataNode3392NodeManager#查看HDFSWeb页面http://bigdata-senior01.chybinmy.com:50070/#查看YARNWeb页面http://bigdata-senior02.chybinmy.com:8088/cluster测试Job
我们这里用hadoop自带的wordcount例子来在本地模式下测试跑mapreduce。
#准备mapreduce输入文件wc.input[hadoop@bigdata-senior01modules]$cat/opt/data/wc.inputhadoopmapreducehivehbasesparkstormsqoophadoophivesparkhadoop#在HDFS创建输入目录input[hadoop@bigdata-senior01hadoop-2.5.0]$bin/hdfsdfs-mkdir/input#将wc.input上传到HDFS[hadoop@bigdata-senior01hadoop-2.5.0]$bin/hdfsdfs-put/opt/data/wc.input/input/wc.input#运行hadoop自带的mapreduceDemo[hadoop@bigdata-senior01hadoop-2.5.0]$bin/yarnjarshare/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jarwordcount/input/wc.input/output#查看输出文件[hadoop@bigdata-senior01hadoop-2.5.0]$bin/hdfsdfs-ls/outputFound2items-rw-r–r–3hadoopsupergroup02016-07-1416:36/output/_SUCCESS-rw-r–r–3hadoopsupergroup602016-07-1416:36/output/part-r-00000
推荐阅读
聊几个与赚钱相关的小事情
MySQL太慢?试试这些诊断思路和工具
21个令程序员泪流满面的瞬间
Jenkins与Docker的自动化CI/CD实战
2018互联网科技公司中秋月饼大PK,福利争霸
送你 8 张图,好好理解一下。
与其抖音,不如学习
·end·
—写文不易,你的转发就是对我最大的支持—
我们一起愉快的玩耍吧