统计学习的方法很多,今天我们就从《西游记》中取经,学习变量类型。
之前一篇推文“一张脑图搞定!统计方法选择”中提到,“变量确定方法”。作为统计的初学者,一定要掌握变量类型。
01什么是变量?
简而言之,变量就是变化的数量。比如,你的心跳忽高忽低变化,你口袋里的钱,忽多忽少变化,这里的心跳和钱就是变量。
那么变量有什么用呢?变量的本质就是一个量,也就是说变量里只装数据。
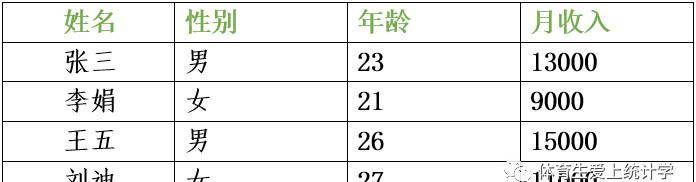
比如,我们收集到教练员的月收入,张三1.3万,李娟0.9万……。收集好之后,把这一列数据排成一列。给这个变量命个名,叫“收入变量”。
当然,我们还不止只收集教练员的收入,我还要收集他们性别,年龄等。这些变量组合在一起,就组成了一个表格。表格有很多行,也有很多列。
通常说行代表ID。对教练员的数据来说,行就是一个一个人,张三占一行,李娟占一行。列就是一个个变量,姓名、性别、年龄和收入等。
聪明的你可能发现,性别这个变量有些特殊。一般而言,性别为男性或者女性,这不是数字。可是,变量只能装数据的呀。怎么办呢?是个小麻烦。这时候,我们要学会“编码”。编码的意思就是,我们规定男性编码为0,女性编码为1。就可以用0和1代替性别变量中的男男女女。同理也可以对每名教练员姓名进行编码,分别用1 2 3 4代替姓名。
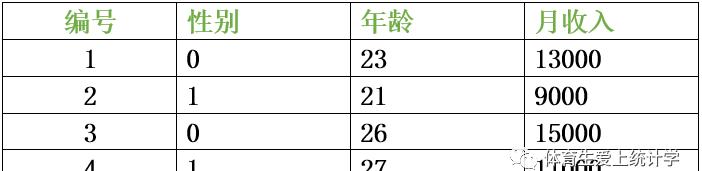
你可能还会问,为什么一定要把男性编码为0呢?可不可以反过来把女性编码为0,男性编码为1呢?当然可以随便编,你还可以把男性编码为250,把女性编码为520。
可是,你这么做,别人可能不太容易理解,也不利于后期处理,处理过程还容易出错,你何必把编码弄得这么复杂。所以,编码以简单、方便容易理解为原则。
这样我们有三层概念:数据——变量——表格。
数据的级别最低,是一个变量的具体数值;
变量是一组数据的集合,代表事物一个维度的信息;
表格的级别最高,是各个变量,也就是事物各个维度信息的集合。
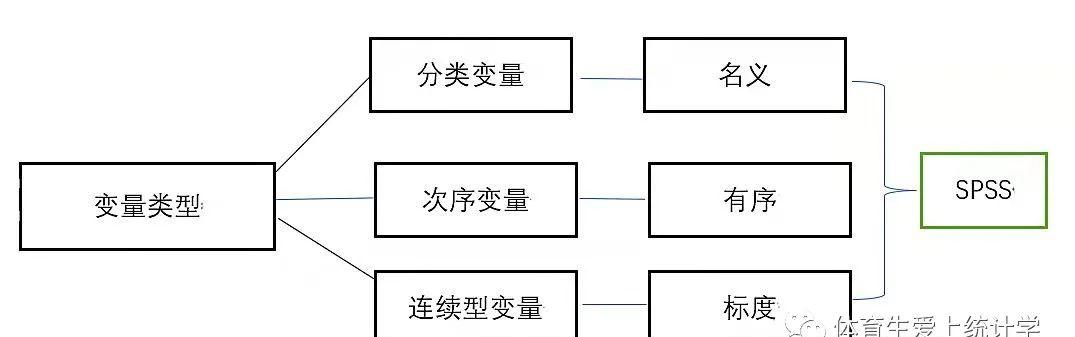
02变量有哪些类型?搞明白了这一点,接下来就可以学习变量类型了。我们别看现实世界的数据千差万别,归类方法也多种,在统计学中,我们将其归为三大类,分别是分类变量、次序变量和连续型变量。由于变量就是变化的数值,所以有些教材中也将其称之为分类数据、次序数据和连续型数据。听起来有很多陌生名词,好像很难记。宣明栋老师在《数据思维课》借鉴了《西游记》人物来帮助大家理解变量类型,我也效仿之。《西游记》的取经队伍有四位,我们借用三位就好了,分别是唐僧、沙和尚和孙悟空。
 第一种:分类变量,“唐僧变量”。我们知道,唐僧的思维是非此即彼的、非黑即白,给所有的东西分类,不是行,就是不行,不是好人,就是坏人,没有中间状态。分类变量也是这样。典型的就是性别,相同的还有民族、婚姻状况、出过国没有出过国等,都是分类变量,它没有大小之分,只有区别功能。依据分类数量,我们可以分成二分类变量和多分类变量。像性别分成男、女,属于二分类;而血型分成A、B、O、AB四大类,属于多分类变量。
第一种:分类变量,“唐僧变量”。我们知道,唐僧的思维是非此即彼的、非黑即白,给所有的东西分类,不是行,就是不行,不是好人,就是坏人,没有中间状态。分类变量也是这样。典型的就是性别,相同的还有民族、婚姻状况、出过国没有出过国等,都是分类变量,它没有大小之分,只有区别功能。依据分类数量,我们可以分成二分类变量和多分类变量。像性别分成男、女,属于二分类;而血型分成A、B、O、AB四大类,属于多分类变量。

虽然“分类”这个概念挺简单,但还是要提示一点——设置分类既要完备,又要排他。
举个例子。我们填各种表时,经常有一项“婚姻状况”,一般会有四个选项——未婚、已婚、离婚和丧偶。完备是指这四个选项包括所有婚姻状态;而排他是指这四个选项相互排斥,不存在交叉。
如果在婚姻状况中添加“同居”这个选项,那么它会与未婚和离婚这两个选项存在交叉。因为有人可能是未婚同居,也可能离婚同居,让人无法填写。
第二种:次序变量,“沙和尚变量”。为什么叫沙和尚变量呢?因为沙和尚工作都要找领导。唐僧在的时候,就找唐僧;唐僧被抓了,就找大师兄孙悟空;孙悟空不在了,就找二师兄猪八戒。你看,特别有次序。

比如这样提问:“我特别喜欢运动,这句话符合你吗”,是非常符合、符合、不确定、不符合,还是非常不符合呢?这个问题测量出来的结果就是次序数据。
本质上,次序变量还是分类变量,但是多了一个大小顺序的信息。所以有些教材分成将次序变量称为有序分类变量,而分类变量称为无序分类变量。
注意,次序变量只能说明几个选项是有顺序的,只有大小之分,而不关心选项之间差距是否相同。就像刚才那个问题,回答“非常符合”和“符合”之间、“符合”和“不确定”之间,程度是否相同,是无法确定的。
第三种:连续型变量,“孙悟空变量”。
为什么是孙悟空呢?因为孙悟空的武器是金箍棒,可以任意放大缩小。它可以取任意数值。比如我们月收入变量,可以取5000, 5001,甚至可以取5001.1元任意数值。

连续型变量的特征是,各种数据之间不但有大小之分,而且还有相同间隔,比如2000元、3000元和4000元的之间的间隔是相等的,而且还可以做乘除运算,比如4000元收入是2000元收入的两倍。
小结一下:
变量一共有三种类型,分别是分类变量、次序变量、连续型变量,分别对应唐僧、沙和尚和孙悟空。在SPSS软件中,这三类变量就对应了名义、有序和标度。
03变量类型有何指导意义?
了解这些变量类型,我认为至少有两方面作用。
第一,能指导我们收集数据
比如收入变量,本来是连续型变量,但如果把收入划分成四个档次——贫困人口、工薪阶层、中产阶级和富人群体,连续型就变成了次序变量。
但是,反过来就不行。先有工薪阶层、中产阶级这些有序分类变量之后,就没有办法转化为收入的连续型数据。这就叫向下兼容。
向下兼容的本质是说,从分类变量、次序变量和连续型变量。越往后,变量拥有的信息越多;反之,就是一个丢失信息的过程。这也给我们一个提示:收集数据的时候,尽量多收集连续型数据,以后需要的话可以向下转换。
第二,能指导我们选择统计方法
简单取个例子,得到教练员的收入情况,这是连续型变量,我们就可以计算平均值,比较收入的高低。但如果是得到教练员的性别呢?这是分类变量,计算平均性别就很荒谬了。
更重要的是,变量指导我们统计方法,详细请查看之前的推文,一张脑图搞定,统计方法选择。
最后,虽然我想说的是,尽量多收集连续型数据,但也不是说连续型变量就比其他变量更好。每一种类型的数据都有它的用处,这里没有鄙视链。
就像唐僧一样,虽然他打妖怪没啥功劳,还经常惹事,但每当遇到困难时,就采用二分类变量思维,目标明确,坚定地说:“徒弟们,别往东看了;咱们向西出发,走起”
划重点、
1.变量就是变化的数量。数据是一个变量的具体值,变量代表一个维度的信息,表格是各种维度信息的集合。
2.变量可分为分类变量、次序变量和连续型变量。其中,分类变量只能用于区别;次序变量能比较大小;连续型变量具有等距离和等比例特性。
3.了解变量类型,可指导我们收集数据和选择统计方法。
END