“
在不用爬虫框架的情况下,我经过多方学习,尝试实现了一个分布式爬虫系统,并且可以将数据保存到不同地方,类似 MySQL、HBase 等。

因为此系统基于面向接口的编码思想来开发,所以具有一定的扩展性,有兴趣的朋友直接看一下代码,就能理解其设计思想。
虽然代码目前来说很多地方还是比较紧耦合,但只要花些时间和精力,很多都是可抽取出来并且可配置化的。
因为时间的关系,我只写了京东和苏宁易购两个网站的爬虫,但是完全可以实现不同网站爬虫的随机调度,基于其代码结构,再写国美、天猫等的商品爬取,难度不大,但是估计需要花些时间和精力。
因为在解析网页的数据时,比如我在爬取苏宁易购商品的价格时,价格是异步获取的,并且其 API 是一长串的数字组合,我花了几个小时的时间才发现其规律,当然也承认,我的经验不足。
如何实现分布式?同一个程序打包后分发到不同的节点运行时,不影响整体的数据爬取。
如何实现URL 随机循环调度?核心是针对不同的顶级域名做随机。
如何定时向 URL 仓库中添加种子 URL?达到不让爬虫系统停下来的目的。
如何实现对爬虫节点程序的监控,并能够发邮件报警?
如何实现一个随机 IP 代理库?目的跟第 2 点有点类似,都是为了反反爬虫。
下面会针对这个系统来做一个整体的基本介绍,我在代码中都有非常详细的注释,有兴趣的朋友可以参考一下代码,最后我会给出一些我爬虫时的数据分析。
另外需要注意的是,这个爬虫系统是基于 Java 实现的,但是语言本身仍然不是最重要的,有兴趣的朋友可以尝试用 Python 实现。
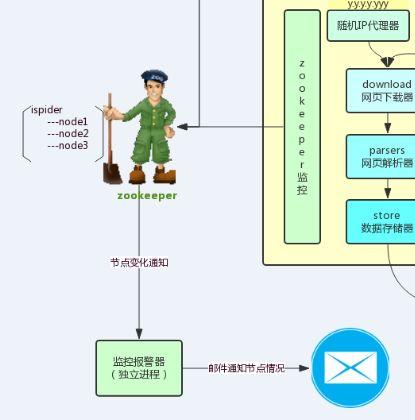
分布式爬虫系统架构
整体系统架构如下:
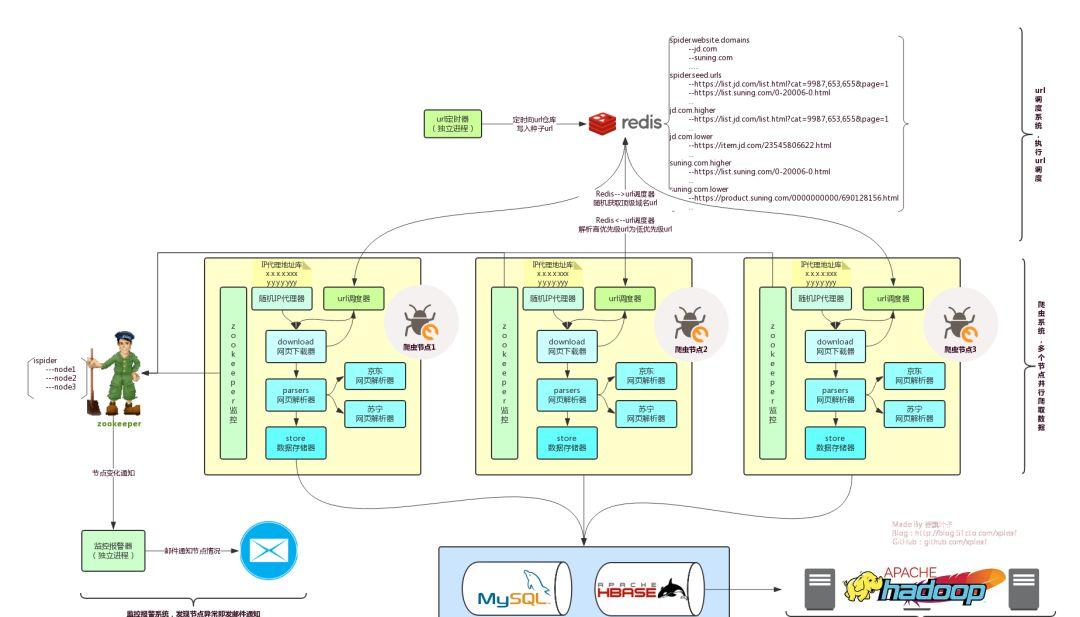
从上面的架构可以看出,整个系统主要分为三个部分:
爬虫系统
URL 调度系统
监控报警系统
爬虫系统是用来爬取数据的,因为系统设计为分布式,因此,爬虫程序本身可以运行在不同的服务器节点上。
URL 调度系统核心在于 URL 仓库,所谓的 URL 仓库其实就是用 Redis 保存了需要爬取的 URL 列表,并且在我们的 URL 调度器中根据一定的策略来消费其中的 URL。从这个角度考虑,URL 仓库其实也是一个 URL 队列。
监控报警系统主要是对爬虫节点进行监控,虽然并行执行的爬虫节点中的某一个挂掉了对整体数据爬取本身没有影响(只是降低了爬虫的速度),但是我们还是希望能够主动接收到节点挂掉的通知,而不是被动地发现。
下面将针对以上三个方面并结合部分代码片段来对整个系统的设计思路做一些基本的介绍。
爬虫系统
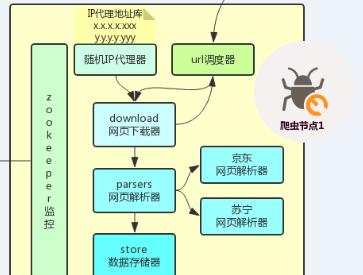
爬虫系统是一个独立运行的进程,我们把我们的爬虫系统打包成 jar 包,然后分发到不同的节点上执行,这样并行爬取数据可以提高爬虫的效率。(说明:ZooKeeper 监控属于监控报警系统,URL 调度器属于 URL 调度系统)
随机 IP 代理器
加入随机 IP 代理主要是为了反反爬虫,因此如果有一个 IP 代理库,并且可以在构建 http 客户端时随机地使用不同的代理,那么对我们进行反反爬虫会有很大的帮助。
# IPProxyRepository.txt58.60.255.104:8118219.135.164.245:312827.44.171.27:9999219.135.164.245:312858.60.255.104:811858.252.6.165:9000……
需要注意的是,上面的代理 IP 是我在西刺代理上拿到的一些代理 IP,不一定可用,建议是自己花钱购买一批代理 IP,这样可以节省很多时间和精力去寻找代理 IP。
然后在构建 http 客户端的工具类中,当第一次使用工具类时,会把这些代理 IP 加载进内存中,加载到 Java 的一个 HashMap:
之后,在每次构建 http 客户端时,都会先到 map 中看是否有代理 IP,有则使用,没有则不使用代理:
随机代理对象则通过下面的方法生成:
/** * 随机返回一个代理对象 * * @return */public static HttpHost getRandomProxy() { // 随机获取host:port,并构建代理对象 Random random = new Random(); String host = keysArray[random.nextInt(keysArray.length)]; int port = IPProxyRepository.get(host); HttpHost proxy = new HttpHost(host, port); // 设置http代理 return proxy;}
这样,通过上面的设计,基本就实现了随机 IP 代理器的功能,当然,其中还有很多可以完善的地方。
比如,当使用这个 IP 代理而请求失败时,是否可以把这一情况记录下来;当超过一定次数时,再将其从代理库中删除,同时生成日志供开发人员或运维人员参考,这是完全可以实现的,不过我就不做这一步功能了。
网页下载器
网页下载器就是用来下载网页中的数据,主要基于下面的接口开发:
/** * 网页数据下载 */public interface IDownload { /** * 下载给定url的网页数据 * @param url * @return */ public Page download(String url);}
基于此,在系统中只实现了一个 http get 的下载器,但是也可以完成我们所需要的功能了:
/** * 数据下载实现类 */public class HttpGetDownloadImpl implements IDownload { @Override public Page download(String url) { Page page = new Page(); String content = HttpUtil.getHttpContent(url); // 获取网页数据 page.setUrl(url); page.setContent(content); return page; }}
网页解析器
网页解析器就是把下载的网页中我们感兴趣的数据解析出来,并保存到某个对象中,供数据存储器进一步处理以保存到不同的持久化仓库中,其基于下面的接口进行开发:
/** * 网页数据解析 */public interface IParser { public void parser(Page page);}
网页解析器在整个系统的开发中也算是比较重头戏的一个组件,功能不复杂,主要是代码比较多,针对不同的商城不同的商品,对应的解析器可能就不一样了。
因此需要针对特别的商城的商品进行开发,因为很显然,京东用的网页模板跟苏宁易购的肯定不一样,天猫用的跟京东用的也肯定不一样。
所以这个完全是看自己的需要来进行开发了,只是说,在解析器开发的过程当中会发现有部分重复代码,这时就可以把这些代码抽象出来开发一个工具类了。
目前在系统中爬取的是京东和苏宁易购的手机商品数据,因此就写了这两个实现类:
/** * 解析京东商品的实现类 */public class JDHtmlParserImpl implements IParser { ……}/** * 苏宁易购网页解析 */public class SNHtmlParserImpl implements IParser { ……}
数据存储器

数据存储器主要是将网页解析器解析出来的数据对象保存到不同的表格,而对于本次爬取的手机商品,数据对象是下面一个 Page 对象:
对应的,在 MySQL 中,表数据结构如下:
而在 HBase 中的表结构则为如下:
## cf1 存储 id source price comment brand url## cf2 存储 title params imgUrlcreate ‘phone’, ‘cf1’, ‘cf2’## 在HBase shell中查看创建的表hbase(main):135:0> desc ‘phone’Table phone is ENABLED phone COLUMN FAMILIES DESCRIPTION {NAME => ‘cf1’, BLOOMFILTER => ‘ROW’, VERSIONS => ‘1’, IN_MEMORY => ‘false’, KEEP_DELETED_CELLS => ‘FALSE’, DATA_BLOCK_ENCODING => ‘NONE’, TTL => ‘FOREVER’, COMPRESSION => ‘NONE’, MIN_VERSIONS => ‘0’, BLOCKCACHE => ‘true’, BLOCKSIZE => ‘65536’, REPLICATION_SCOPE => ‘0’} {NAME => ‘cf2’, BLOOMFILTER => ‘ROW’, VERSIONS => ‘1’, IN_MEMORY => ‘false’, KEEP_DELETED_CELLS => ‘FALSE’, DATA_BLOCK_ENCODING => ‘NONE’, TTL => ‘FOREVER’, COMPRESSION => ‘NONE’, MIN_VERSIONS => ‘0’, BLOCKCACHE => ‘true’, BLOCKSIZE => ‘65536’, REPLICATION_SCOPE => ‘0’} 2 row(s) in 0.0350 seconds
即在 HBase 中建立了两个列族,分别为 cf1、cf2,其中 cf1 用来保存 id source price comment brand url 字段信息;cf2 用来保存 title params imgUrl 字段信息。
不同的数据存储用的是不同的实现类,但是其都是基于下面同一个接口开发的:
/** * 商品数据的存储 */public interface IStore { public void store(Page page);}
然后基于此开发了 MySQL 的存储实现类、HBase 的存储实现类还有控制台的输出实现类,如 MySQL 的存储实现类,其实就是简单的数据插入语句:
/** * 使用dbc数据库连接池将数据写入mysql表中 */public class MySQLStoreImpl implements IStore { private QueryRunner queryRunner = new QueryRunner(DBCPUtil.getDataSource()); @Override public void store(Page page) { String sql = “insert into phone(id, source, brand, title, price, comment_count, url, img_url, params) values(?, ?, ?, ?, ?, ?, ?, ?, ?)”; try { queryRunner.update(sql, page.getId(), page.getSource(), page.getBrand(), page.getTitle(), page.getPrice(), page.getCommentCount(), page.getUrl(), page.getImgUrl(), page.getParams()); } catch (SQLException e) { e.printStackTrace(); } }}
而 HBase 的存储实现类,则是 HBase Java API 的常用插入语句代码:
……// cf1:pricePut pricePut = new Put(rowKey);// 必须要做是否为null判断,否则会有空指针异常pricePut.addColumn(cf1, “price”.getBytes(), page.getPrice() != null ? String.valueOf(page.getPrice()).getBytes() : “”.getBytes());puts.add(pricePut);// cf1:commentPut commentPut = new Put(rowKey);commentPut.addColumn(cf1, “comment”.getBytes(), page.getCommentCount() != null ? String.valueOf(page.getCommentCount()).getBytes() : “”.getBytes());puts.add(commentPut);// cf1:brandPut brandPut = new Put(rowKey);brandPut.addColumn(cf1, “brand”.getBytes(), page.getBrand() != null ? page.getBrand().getBytes() : “”.getBytes());puts.add(brandPut);……
当然,至于要将数据存储在哪个地方,在初始化爬虫程序时,是可以手动选择的:
// 3.注入存储器iSpider.setStore(new HBaseStoreImpl());
目前还没有把代码写成可以同时存储在多个地方,按照目前代码的架构,要实现这一点也比较简单,修改一下相应代码就好了。
实际上,是可以先把数据保存到 MySQL 中,然后通过 Sqoop 导入到 HBase 中,详细操作可以参考我写的 Sqoop 文章。
仍然需要注意的是,如果确定需要将数据保存到 HBase 中,请保证你有可用的集群环境,并且需要将如下配置文档添加到 classpath 下:
core-site.xmlhbase-site.xmlhdfs-site.xml
对大数据感兴趣的同学可以折腾一下这一点,如果之前没有接触过的,直接使用 MySQL 存储就好了,只需要在初始化爬虫程序时注入 MySQL 存储器即可:
// 3.注入存储器iSpider.setStore(new MySQLStoreImpl());
URL 调度系统
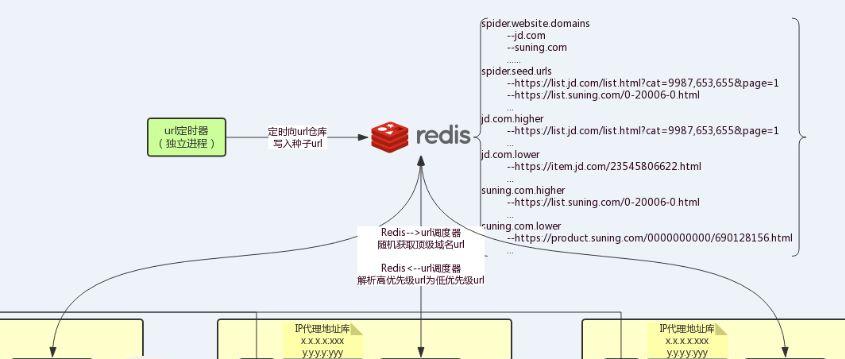
URL 调度系统是实现整个爬虫系统分布式的桥梁与关键,正是通过 URL 调度系统的使用,才使得整个爬虫系统可以较为高效(Redis 作为存储)随机地获取 URL,并实现整个系统的分布式。
URL 仓库
正是这样,才能保证我们的程序实现分布式,只要保存了 URL 是唯一的,这样不管我们的爬虫程序有多少个,最终保存下来的数据都是只有唯一一份的,而不会重复。
另外,在我们的 URL 仓库中,主要保存了下面的数据:
种子 URL 列表,Redis 的数据类型为 list
种子 URL 是持久化存储的,一定时间后,由 URL 定时器通过种子 URL 获取 URL,并将其注入到我们的爬虫程序需要使用的高优先级 URL 队列中。
这样就可以保证我们的爬虫程序可以源源不断地爬取数据而不需要中止程序的执行。
高优先级 URL 队列,Redis 的数据类型为 set
什么是高优先级 URL 队列?其实它就是用来保存列表 URL 的。那么什么是列表 URL 呢?
说白了就是一个列表中含有多个商品,以京东为例,我们打开一个手机列表:
通过对每个高级 URL 的解析,我们可以获取到非常多的具体商品 URL,而具体的商品 URL,就是低优先 URL,其会保存到低优先级 URL 队列中。
那么以这个系统为例,保存的数据类似如下:
jd.com.higher –https://list.jd.com/list.html?cat=9987,653,655&page=1 … suning.com.higher –https://list.suning.com/0-20006-0.html …
低优先级 URL 队列,Redis 的数据类型为 set
低优先级 URL 其实就是具体某个商品的 URL,如下面一个手机商品:
通过下载该 URL 的数据,并对其进行解析,就能够获取到我们想要的数据。
那么以这个系统为例,保存的数据类似如下:
jd.com.lower –https://item.jd.com/23545806622.html …suning.com.lower –https://product.suning.com/0000000000/690128156.html …
URL 调度器
所谓 URL 调度器,就是 URL 仓库 Java 代码的调度策略,不过因为其核心在于调度,所以将其放到 URL 调度器中来进行说明,目前其调度基于以下接口开发:
/** * url 仓库 * 主要功能: * 向仓库中添加url(高优先级的列表,低优先级的商品url) * 从仓库中获取url(优先获取高优先级的url,如果没有,再获取低优先级的url) * */public interface IRepository { /** * 获取url的方法 * 从仓库中获取url(优先获取高优先级的url,如果没有,再获取低优先级的url) * @return */ public String poll(); /** * 向高优先级列表中添加商品列表url * @param highUrl */ public void offerHigher(String highUrl); /** * 向低优先级列表中添加商品url * @param lowUrl */ public void offerLower(String lowUrl);}
其基于 Redis 作为 URL 仓库的实现如下:
/** * 基于Redis的全网爬虫,随机获取爬虫url: * * Redis中用来保存url的数据结构如下: * 1.需要爬取的域名集合(存储数据类型为set,这个需要先在Redis中添加) * key * spider.website.domains * value(set) * jd.com suning.com gome.com * key由常量对象SpiderConstants.SPIDER_WEBSITE_DOMAINS_KEY 获得 * 2.各个域名所对应的高低优先url队列(存储数据类型为list,这个由爬虫程序解析种子url后动态添加) * key * jd.com.higher * jd.com.lower * suning.com.higher * suning.com.lower * gome.com.higher * gome.come.lower * value(list) * 相对应需要解析的url列表 * key由随机的域名 常量 SpiderConstants.SPIDER_DOMAIN_HIGHER_SUFFIX或者SpiderConstants.SPIDER_DOMAIN_LOWER_SUFFIX获得 * 3.种子url列表 * key * spider.seed.urls * value(list) * 需要爬取的数据的种子url * key由常量SpiderConstants.SPIDER_SEED_URLS_KEY获得 * * 种子url列表中的url会由url调度器定时向高低优先url队列中 */public class RandomRedisRepositoryImpl implements IRepository { /** * 构造方法 */ public RandomRedisRepositoryImpl() { init(); } /** * 初始化方法,初始化时,先将redis中存在的高低优先级url队列全部删除 * 否则上一次url队列中的url没有消耗完时,再停止启动跑下一次,就会导致url仓库中有重复的url */ public void init() { Jedis jedis = JedisUtil.getJedis(); Set<String> domains = jedis.smembers(SpiderConstants.SPIDER_WEBSITE_DOMAINS_KEY); String higherUrlKey; String lowerUrlKey; for(String domain : domains) { higherUrlKey = domain SpiderConstants.SPIDER_DOMAIN_HIGHER_SUFFIX; lowerUrlKey = domain SpiderConstants.SPIDER_DOMAIN_LOWER_SUFFIX; jedis.del(higherUrlKey, lowerUrlKey); } JedisUtil.returnJedis(jedis); } /** * 从队列中获取url,目前的策略是: * 1.先从高优先级url队列中获取 * 2.再从低优先级url队列中获取 * 对应我们的实际场景,应该是先解析完列表url再解析商品url * 但是需要注意的是,在分布式多线程的环境下,肯定是不能完全保证的,因为在某个时刻高优先级url队列中 * 的url消耗完了,但实际上程序还在解析下一个高优先级url,此时,其它线程去获取高优先级队列url肯定获取不到 * 这时就会去获取低优先级队列中的url,在实际考虑分析时,这点尤其需要注意 * @return */ @Override public String poll() { // 从set中随机获取一个顶级域名 Jedis jedis = JedisUtil.getJedis(); String randomDomain = jedis.srandmember(SpiderConstants.SPIDER_WEBSITE_DOMAINS_KEY); // jd.com String key = randomDomain SpiderConstants.SPIDER_DOMAIN_HIGHER_SUFFIX; // jd.com.higher String url = jedis.lpop(key); if(url == null) { // 如果为null,则从低优先级中获取 key = randomDomain SpiderConstants.SPIDER_DOMAIN_LOWER_SUFFIX; // jd.com.lower url = jedis.lpop(key); } JedisUtil.returnJedis(jedis); return url; } /** * 向高优先级url队列中添加url * @param highUrl */ @Override public void offerHigher(String highUrl) { offerUrl(highUrl, SpiderConstants.SPIDER_DOMAIN_HIGHER_SUFFIX); } /** * 向低优先url队列中添加url * @param lowUrl */ @Override public void offerLower(String lowUrl) { offerUrl(lowUrl, SpiderConstants.SPIDER_DOMAIN_LOWER_SUFFIX); } /** * 添加url的通用方法,通过offerHigher和offerLower抽象而来 * @param url 需要添加的url * @param urlTypeSuffix url类型后缀.higher或.lower */ public void offerUrl(String url, String urlTypeSuffix) { Jedis jedis = JedisUtil.getJedis(); String domain = SpiderUtil.getTopDomain(url); // 获取url对应的顶级域名,如jd.com String key = domain urlTypeSuffix; // 拼接url队列的key,如jd.com.higher jedis.lpush(key, url); // 向url队列中添加url JedisUtil.returnJedis(jedis); }}
通过代码分析也可以知道,其核心就在如何调度 URL 仓库(Redis)中的 URL。
URL 定时器
一段时间后,高优先级 URL 队列和低优先 URL 队列中的 URL 都会被消费完。
为了让程序可以继续爬取数据,同时减少人为的干预,可以预先在 Redis 中插入种子 URL,之后定时让 URL 定时器从种子 URL 中取出 URL存放到高优先级 URL 队列中,以此达到程序定时不间断爬取数据的目的。
URL 消费完毕后,是否需要循环不断爬取数据根据个人业务需求而不同,因此这一步不是必需的,只是也提供了这样的操作。
因为事实上,我们需要爬取的数据也是每隔一段时间就会更新的,如果希望我们爬取的数据也跟着定时更新,那么这时定时器就有非常重要的作用了。
不过需要注意的是,一旦决定需要循环重复爬取数据,则在设计存储器实现时需要考虑重复数据的问题,即重复数据应该是更新操作。
目前在我设计的存储器不包括这个功能,有兴趣的朋友可以自己实现,只需要在插入数据前判断数据库中是否存在该数据即可。
另外需要注意的一点是,URL 定时器是一个独立的进程,需要单独启动。
定时器基于 Quartz 实现,下面是其 job 的代码:
/** * 每天定时从url仓库中获取种子url,添加进高优先级列表 */public class UrlJob implements Job { // log4j日志记录 private Logger logger = LoggerFactory.getLogger(UrlJob.class); @Override public void execute(JobExecutionContext context) throws JobExecutionException { /** * 1.从指定url种子仓库获取种子url * 2.将种子url添加进高优先级列表 */ Jedis jedis = JedisUtil.getJedis(); Set<String> seedUrls = jedis.smembers(SpiderConstants.SPIDER_SEED_URLS_KEY); // spider.seed.urls Redis数据类型为set,防止重复添加种子url for(String seedUrl : seedUrls) { String domain = SpiderUtil.getTopDomain(seedUrl); // 种子url的顶级域名 jedis.sadd(domain SpiderConstants.SPIDER_DOMAIN_HIGHER_SUFFIX, seedUrl); logger.info(“获取种子:{}”, seedUrl); } JedisUtil.returnJedis(jedis);// System.out.println(“Scheduler Job Test…”); }}
调度器的实现如下:
/** * url定时调度器,定时向url对应仓库中存放种子url * * 业务规定:每天凌晨1点10分向仓库中存放种子url */public class UrlJobScheduler { public UrlJobScheduler() { init(); } /** * 初始化调度器 */ public void init() { try { Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler(); // 如果没有以下start方法的执行,则是不会开启任务的调度 scheduler.start(); String name = “URL_SCHEDULER_JOB”; String group = “URL_SCHEDULER_JOB_GROUP”; JobDetail jobDetail = new JobDetail(name, group, UrlJob.class); String cronExpression = “0 10 1 * * ?”; Trigger trigger = new CronTrigger(name, group, cronExpression); // 调度任务 scheduler.scheduleJob(jobDetail, trigger); } catch (SchedulerException e) { e.printStackTrace(); } catch (ParseException e) { e.printStackTrace(); } } public static void main(String[] args) { UrlJobScheduler urlJobScheduler = new UrlJobScheduler(); urlJobScheduler.start(); } /** * 定时调度任务 * 因为我们每天要定时从指定的仓库中获取种子url,并存放到高优先级的url列表中 * 所以是一个不间断的程序,所以不能停止 */ private void start() { while (true) { } }}
监控报警系统
监控报警系统的加入主要是为了让使用者可以主动发现节点宕机,而不是被动地发现,因为实际中爬虫程序可能是持续不断运行的。
并且我们会在多个节点上部署我们的爬虫程序,因此很有必要对节点进行监控,并且在节点出现问题时可以及时发现并修正,需要注意的是,监控报警系统是一个独立的进程,需要单独启动。
基本原理
首先需要先在 ZooKeeper 中创建一个 /ispider 节点:
[zk: localhost:2181(CONNECTED) 1] create /ispider ispiderCreated /ispider
监控报警系统的开发主要依赖于 ZooKeeper 实现,监控程序对 ZooKeeper 下面的这个节点目录进行监听:
[zk: localhost:2181(CONNECTED) 0] ls /ispider[]
爬虫程序启动时会在该节点目录下注册一个临时节点目录:
[zk: localhost:2181(CONNECTED) 0] ls /ispider[192.168.43.166]
当节点出现宕机时,该临时节点目录就会被 ZooKeeper 删除。
[zk: localhost:2181(CONNECTED) 0] ls /ispider[]
同时因为我们监听了节点目录 /ispider,所以当 ZooKeeper 删除其下的节点目录时(或增加一个节点目录),ZooKeeper 会给我们的监控程序发送通知。
即我们的监控程序会得到回调,这样便可以在回调程序中执行报警的系统动作,从而完成监控报警的功能。
ZooKeeper Java API 使用说明
可以使用 ZooKeeper 原生的 Java API,我在另外写的一个 RPC 框架(底层基于 Netty 实现远程通信)中就是使用原生的 API。
不过显然代码会复杂很多,并且本身需要对 ZooKeeper 有更多的学习和了解,这样用起来才会容易一些。
所以为了降低开发的难度,这里使用第三方封装的 API,即 curator,来进行 ZooKeeper 客户端程序的开发。
爬虫系统 ZooKeeper 注册
/** * 注册zk */private void registerZK() { String zkStr = “uplooking01:2181,uplooking02:2181,uplooking03:2181”; int baseSleepTimeMs = 1000; int maxRetries = 3; RetryPolicy retryPolicy = new ExponentialBackoffRetry(baseSleepTimeMs, maxRetries); CuratorFramework curator = CuratorFrameworkFactory.newClient(zkStr, retryPolicy); curator.start(); String ip = null; try { // 向zk的具体目录注册 写节点 创建节点 ip = InetAddress.getLocalHost().getHostAddress(); curator.create().withMode(CreateMode.EPHEMERAL).forPath(“/ispider/” ip, ip.getBytes()); } catch (UnknownHostException e) { e.printStackTrace(); } catch (Exception e) { e.printStackTrace(); }}
应该注意到的是,我们创建的节点为临时节点,要想实现监控报警功能,必须要为临时节点。
监控程序
首先需要先监听 ZooKeeper 中的一个节点目录,在我们的系统中,设计是监听 /ispider 这个节点目录:
public SpiderMonitorTask() { String zkStr = “uplooking01:2181,uplooking02:2181,uplooking03:2181”; int baseSleepTimeMs = 1000; int maxRetries = 3; RetryPolicy retryPolicy = new ExponentialBackoffRetry(baseSleepTimeMs, maxRetries); curator = CuratorFrameworkFactory.newClient(zkStr, retryPolicy); curator.start(); try { previousNodes = curator.getChildren().usingWatcher(this).forPath(“/ispider”); } catch (Exception e) { e.printStackTrace(); }}
在上面注册了 ZooKeeper 中的 watcher,也就是接收通知的回调程序,在该程序中,执行我们报警的逻辑:
/** * 这个方法,当监控的zk对应的目录一旦有变动,就会被调用 * 得到当前最新的节点状态,将最新的节点状态和初始或者上一次的节点状态作比较,那我们就知道了是由谁引起的节点变化 * @param event */@Overridepublic void process(WatchedEvent event) { try { List<String> currentNodes = curator.getChildren().usingWatcher(this).forPath(“/ispider”); // HashSet<String> previousNodesSet = new HashSet<>(previousNodes); if(currentNodes.size() > previousNodes.size()) { // 最新的节点服务,超过之前的节点服务个数,有新的节点增加进来 for(String node : currentNodes) { if(!previousNodes.contains(node)) { // 当前节点就是新增节点 logger.info(“—-有新的爬虫节点{}新增进来”, node); } } } else if(currentNodes.size() < previousNodes.size()) { // 有节点挂了 发送告警邮件或者短信 for(String node : previousNodes) { if(!currentNodes.contains(node)) { // 当前节点挂掉了 得需要发邮件 logger.info(“—-有爬虫节点{}挂掉了”, node); MailUtil.sendMail(“有爬虫节点挂掉了,请人工查看爬虫节点的情况,节点信息为:”, node); } } } // 挂掉和新增的数目一模一样,上面是不包括这种情况的,有兴趣的朋友可以直接实现包括这种特殊情况的监控 previousNodes = currentNodes; // 更新上一次的节点列表,成为最新的节点列表 } catch (Exception e) { e.printStackTrace(); } // 在原生的API需要再做一次监控,因为每一次监控只会生效一次,所以当上面发现变化后,需要再监听一次,这样下一次才能监听到 // 但是在使用curator的API时则不需要这样做}
当然,判断节点是否挂掉,上面的逻辑还是存在一定的问题的,按照上面的逻辑,假如某一时刻新增节点和删除节点事件同时发生,那么其就不能判断出来,所以如果需要更精准的话,可以将上面的程序代码修改一下。
邮件发送模块
下面是爬虫节点挂掉时接收到的邮件:
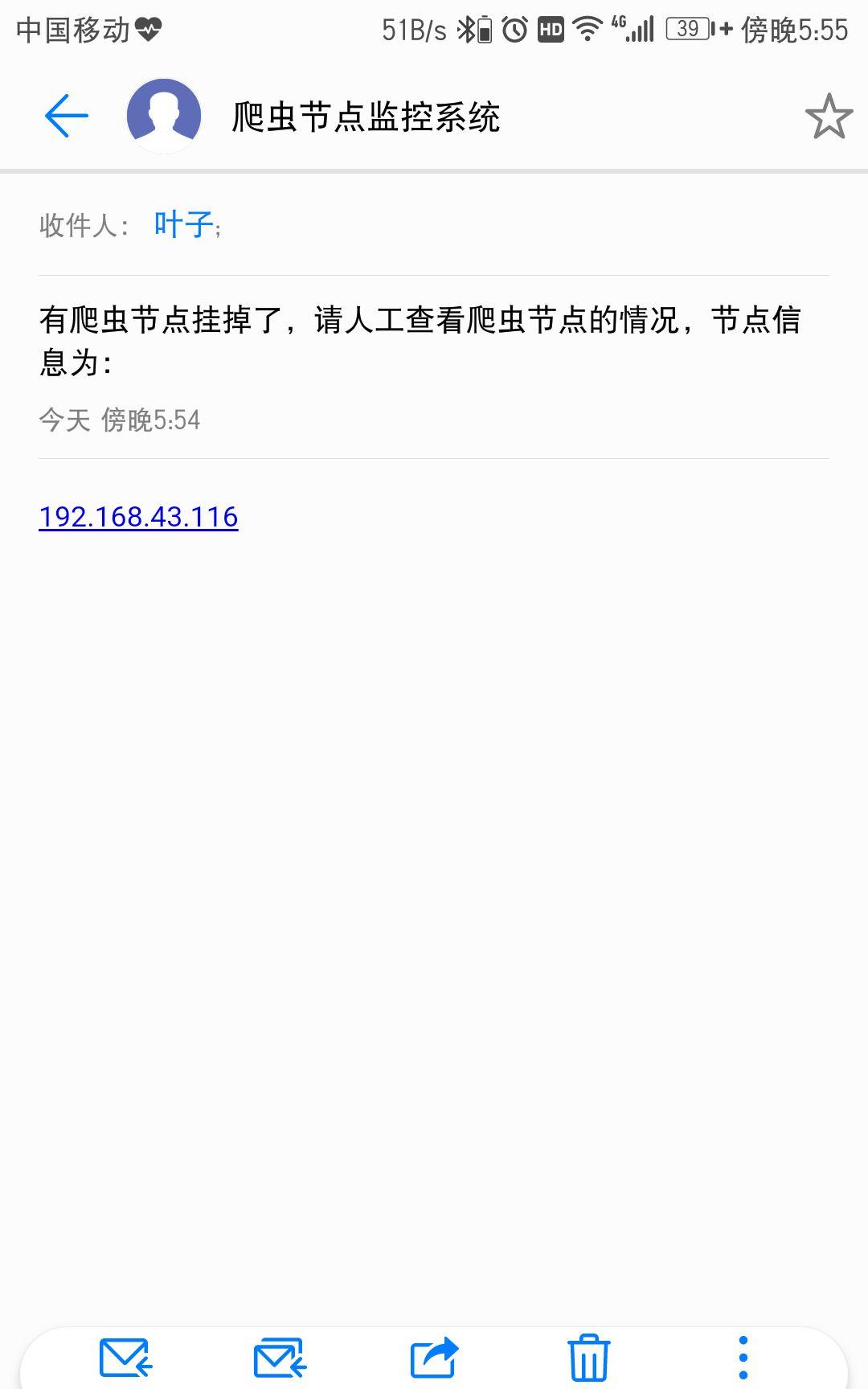
实际上,如果购买了短信服务,那么通过短信 API 也可以向我们的手机发送短信。
实战:爬取京东、苏宁易购全网手机商品数据
因为前面在介绍这个系统的时候也提到了,我只写了京东和苏宁易购的网页解析器,所以接下来也就是爬取其全网的手机商品数据。
环境说明
需要确保 Redis、ZooKeeper 服务可用,另外如果需要使用 HBase 来存储数据,需要确保 Hadoop 集群中的 HBase 可用,并且相关配置文件已经加入到爬虫程序的 classpath 中。
还有一点需要注意的是,URL 定时器和监控报警系统是作为单独的进程来运行的,并且也是可选的。
爬虫结果
进行了两次爬取,分别尝试将数据保存到 MySQL 和 HBase 中,给出如下数据情况。
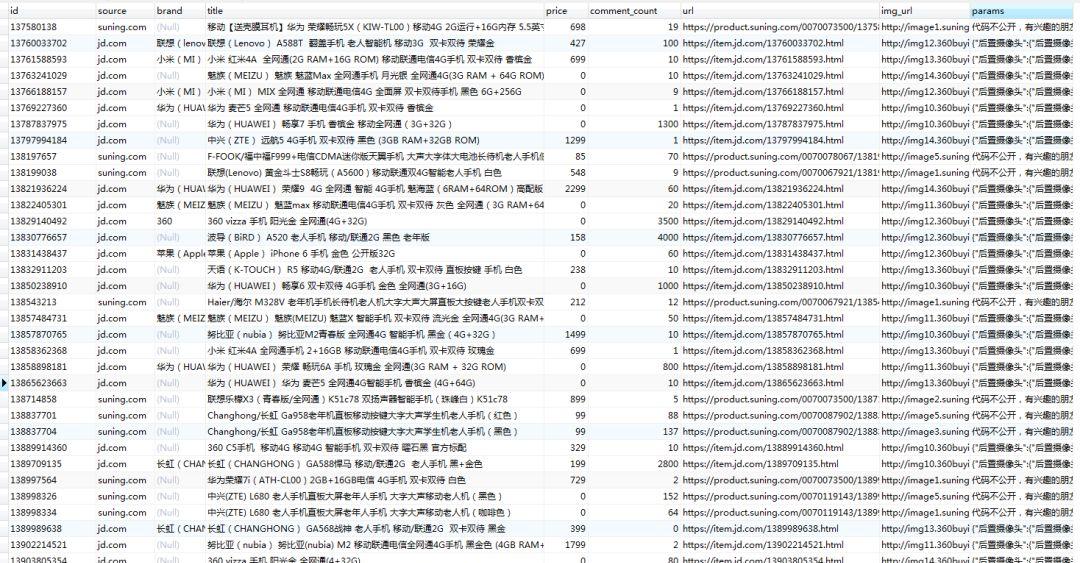
保存到 MySQL
mysql> select count(*) from phone; ———- | count(*) | ———- | 12052 | ———- 1 row in setmysql> select count(*) from phone where source=’jd.com’; ———- | count(*) | ———- | 9578 | ———- 1 row in setmysql> select count(*) from phone where source=’suning.com’; ———- | count(*) | ———- | 2474 | ———- 1 row in set
在可视化工具中查看数据情况:
保存到 HBase
hbase(main):225:0* count ‘phone’Current count: 1000, row: 11155386088_jd.comCurrent count: 2000, row: 136191393_suning.comCurrent count: 3000, row: 16893837301_jd.comCurrent count: 4000, row: 19036619855_jd.comCurrent count: 5000, row: 1983786945_jd.comCurrent count: 6000, row: 1997392141_jd.comCurrent count: 7000, row: 21798495372_jd.comCurrent count: 8000, row: 24154264902_jd.comCurrent count: 9000, row: 25687565618_jd.comCurrent count: 10000, row: 26458674797_jd.comCurrent count: 11000, row: 617169906_suning.comCurrent count: 12000, row: 769705049_suning.com 12348 row(s) in 1.5720 seconds=> 12348
在 HDFS 中查看数据情况:
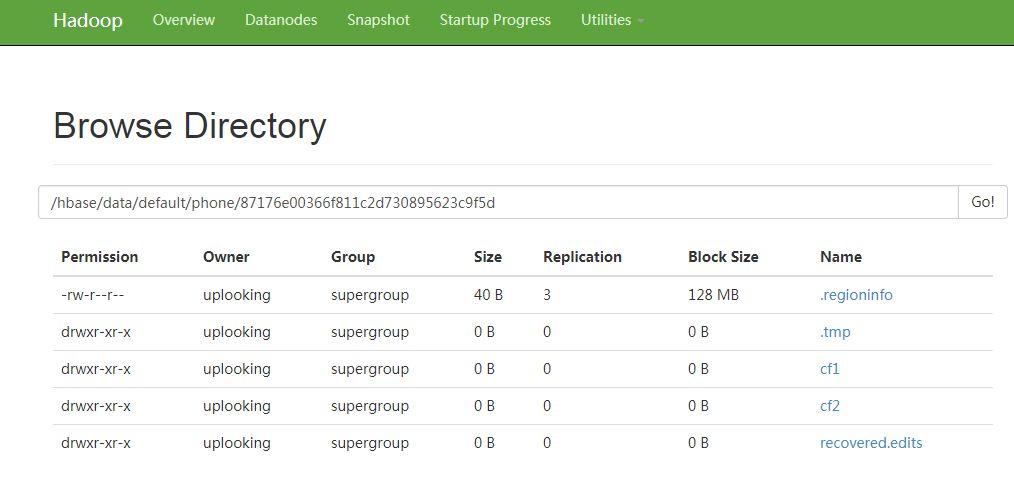
数据量与实际情况分析
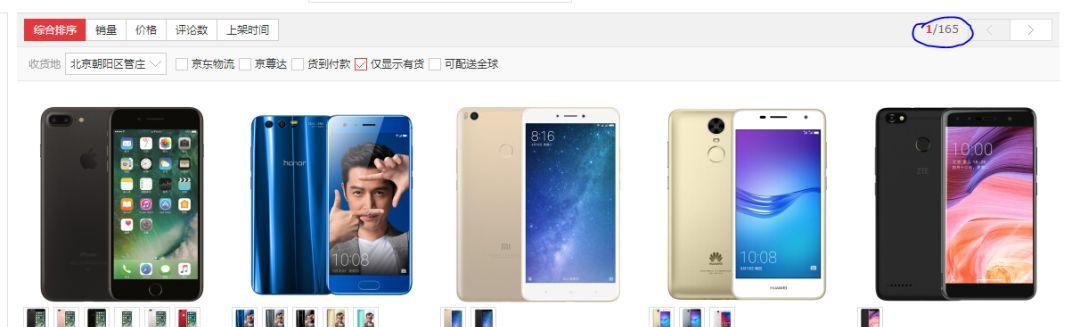
京东:京东手机的列表大概有 160 多页,每个列表有 60 个商品数据,所以总量在 9600 左右,我们的数据基本是符合的。
后面通过日志分析可以知道,一般丢失的数据为连接超时导致的,所以在选取爬虫的环境时,更建议在网络环境好的主机上进行。
一旦出现爬取数据失败的 URL,可以将其加入到重试 URL 队列中,目前这一点功能我是没有做,有兴趣的同学可以试一下。
苏宁易购:再来看看苏宁的数据,其有 100 页左右的手机列表,每页也是 60 个商品数据,所以总量在 6000 左右。
但可以看到,我们的数据却只有 3000 这样的数量级(缺少的依然是频繁爬取造成的连接失败问题),这是为什么呢?
这是因为,打开苏宁的某个列表页面后,其是先加载 30 个商品,当鼠标向下滑动时,才会通过另外的 API 去加载其他的 30 个商品数据,每一个列表页面都是如此,所以,实际上,我们是缺少了一半的商品数据没有爬取。
知道这个原因之后,实现也不难,但是因为时间关系,我就没有做了,有兴趣的朋友折腾一下吧。
通过日志分析爬虫系统的性能
在我们的爬虫系统中,每个关键的地方,如网页下载、数据解析等都是有打 logger 的,所以通过日志,可以大概分析出相关的时间参数。
2018-04-01 21:26:03 [pool-1-thread-1] [cn.xpleaf.spider.utils.HttpUtil] [INFO] – 下载网页:https://list.jd.com/list.html?cat=9987,653,655&page=1,消耗时长:590 ms,代理信息:null:null2018-04-01 21:26:03 [pool-1-thread-1] [cn.xpleaf.spider.core.parser.Impl.JDHtmlParserImpl] [INFO] – 解析列表页面:https://list.jd.com/list.html?cat=9987,653,655&page=1, 消耗时长:46ms2018-04-01 21:26:03 [pool-1-thread-3] [cn.xpleaf.spider.core.parser.Impl.SNHtmlParserImpl] [INFO] – 解析列表页面:https://list.suning.com/0-20006-0.html, 消耗时长:49ms2018-04-01 21:26:04 [pool-1-thread-5] [cn.xpleaf.spider.utils.HttpUtil] [INFO] – 下载网页:https://item.jd.com/6737464.html,消耗时长:219 ms,代理信息:null:null2018-04-01 21:26:04 [pool-1-thread-2] [cn.xpleaf.spider.utils.HttpUtil] [INFO] – 下载网页:https://list.jd.com/list.html?cat=9987,653,655&page=2&sort=sort_rank_asc&trans=1&JL=6_0_0,消耗时长:276 ms,代理信息:null:null2018-04-01 21:26:04 [pool-1-thread-4] [cn.xpleaf.spider.utils.HttpUtil] [INFO] – 下载网页:https://list.suning.com/0-20006-99.html,消耗时长:300 ms,代理信息:null:null2018-04-01 21:26:04 [pool-1-thread-4] [cn.xpleaf.spider.core.parser.Impl.SNHtmlParserImpl] [INFO] – 解析列表页面:https://list.suning.com/0-20006-99.html, 消耗时长:4ms……2018-04-01 21:27:49 [pool-1-thread-3] [cn.xpleaf.spider.utils.HttpUtil] [INFO] – 下载网页:https://club.jd.com/comment/productCommentSummaries.action?referenceIds=23934388891,消耗时长:176 ms,代理信息:null:null2018-04-01 21:27:49 [pool-1-thread-3] [cn.xpleaf.spider.core.parser.Impl.JDHtmlParserImpl] [INFO] – 解析商品页面:https://item.jd.com/23934388891.html, 消耗时长:413ms2018-04-01 21:27:49 [pool-1-thread-2] [cn.xpleaf.spider.utils.HttpUtil] [INFO] – 下载网页:https://review.suning.com/ajax/review_satisfy/general-00000000010017793337-0070079092—–satisfy.htm,消耗时长:308 ms,代理信息:null:null2018-04-01 21:27:49 [pool-1-thread-2] [cn.xpleaf.spider.core.parser.Impl.SNHtmlParserImpl] [INFO] – 解析商品页面:https://product.suning.com/0070079092/10017793337.html, 消耗时长:588ms……
平均下来,下载一个商品网页数据的时间在 200~500 毫秒不等,当然这个还需要取决于当时的网络情况。
另外,如果想要真正计算爬取一个商品的时间数据,可以通过日志下面的数据来计算:
下载一个商品页面数据的时间
获取价格数据的时间
获取评论数据的时间
在我的主机上(CPU:E5 10核心,内存:32GB,分别开启 1 个虚拟机和 3 个虚拟机),情况如下:

可以看到,当使用 3 个节点时,时间并不会相应地缩小为原来的 1/3,这是因为此时影响爬虫性能的问题主要是网络问题,节点数量多,线程数量大,网络请求也多。
但是带宽一定,并且在没有使用代理的情况,请求频繁,连接失败的情况也会增多,对时间也有一定的影响,如果使用随机代理库,情况将会好很多。
但可以肯定的是,在横向扩展增加爬虫节点之后,确实可以大大缩小我们的爬虫时间,这也是分布式爬虫系统的好处。
爬虫系统中使用的反反爬虫策略
在整个爬虫系统的设计中,主要使用下面的策略来达到反反爬虫的目的:
使用代理来访问–>IP 代理库,随机 IP 代理。
随机顶级域名url 访问–>url 调度系统。
每个线程每爬取完一条商品数据 sleep 一小段时间再进行爬取。
总结
需要说明的是,本系统是基于 Java 实现的,但个人觉得,语言本身依然不是问题,核心在于对整个系统的设计以及理解上。
写此文章是希望分享这样一种分布式爬虫系统的架构给大家,如果对源代码感兴趣,可以到我的 GitHub 上查看。
投稿:有投稿、寻求报道意向技术人请联络 editor@51cto.com

叶泳豪,大数据工程师,华为 HCIE-RS 认证工程师。曾就职于华为、网易等企业,目前专注于大数据领域的学习和研究。









