前言
首先,提前跟大家说一声新年快乐!然后,我们进入正题…
Fiddler是一款十分强大的调试代理工具,这个工具我就不详细介绍了。简单来说,它是通过创建代理,拦截http请求用于分析或修改。
这里就演示一下用Fiddler抓取手机端Bilibili的请求并使用Scrapy编写一个爬取图片的爬虫程序。
准备环境
Python,我用的是3.6,系统是win10
Scrapy框架,安装过程我之前的文章提过
手机…我的是安卓
一个安卓软件,我这里就用Bilibili示范
Fiddler配置
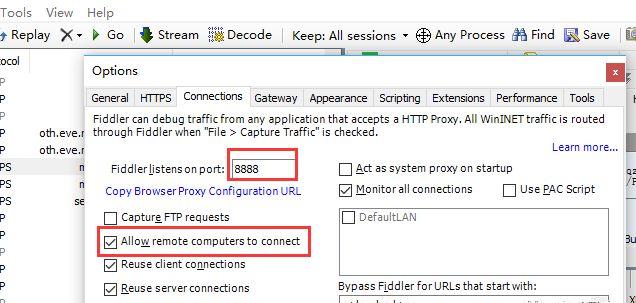
安装我就不说了,说说配置,Tools – Connections这里可以看到默认端口号是很吉利的8888。这里要勾上Allow remote computers to connect。
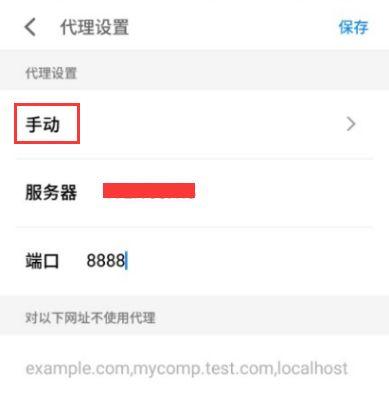
 查看IP手机连接上wifi后,选择代理设置,
查看IP手机连接上wifi后,选择代理设置,
 代理设置下面是给手机安装证书,不安装可能会出现手机设置了代理无法上网的问题。
代理设置下面是给手机安装证书,不安装可能会出现手机设置了代理无法上网的问题。
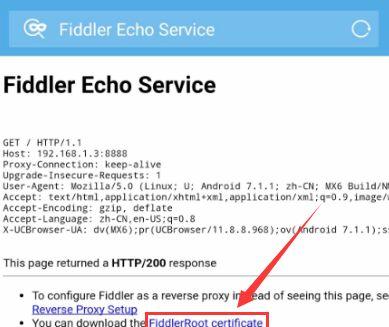 下载证书打开设置 – 安全 – 设备管理与凭证 – 从存储盘安装,差不多都是这个地方,找找应该能找到…
下载证书打开设置 – 安全 – 设备管理与凭证 – 从存储盘安装,差不多都是这个地方,找找应该能找到…
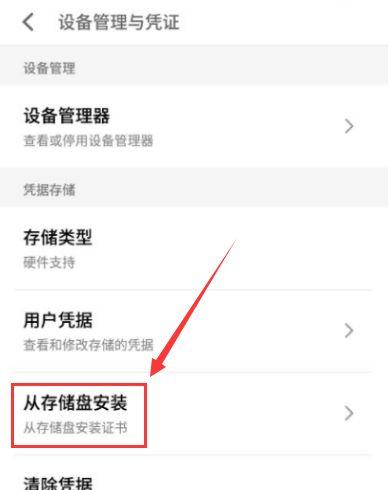 安装证书安装完后可以在用户凭证可以看到:
安装证书安装完后可以在用户凭证可以看到:
 安装完成分析请求
安装完成分析请求
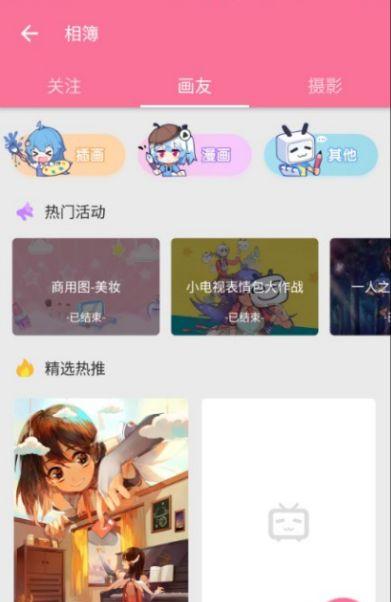
接下来就可以打开Fiddler还有手机端的Bilibili,进行分析了。我这里选择相簿,准备爬取里面的图片。
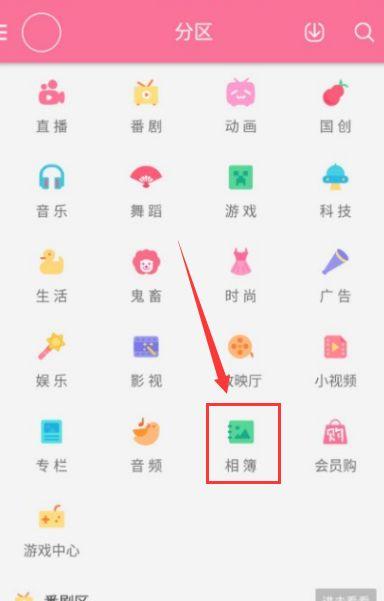 选择相簿下面的精选热推就是我们的目标:
选择相簿下面的精选热推就是我们的目标:
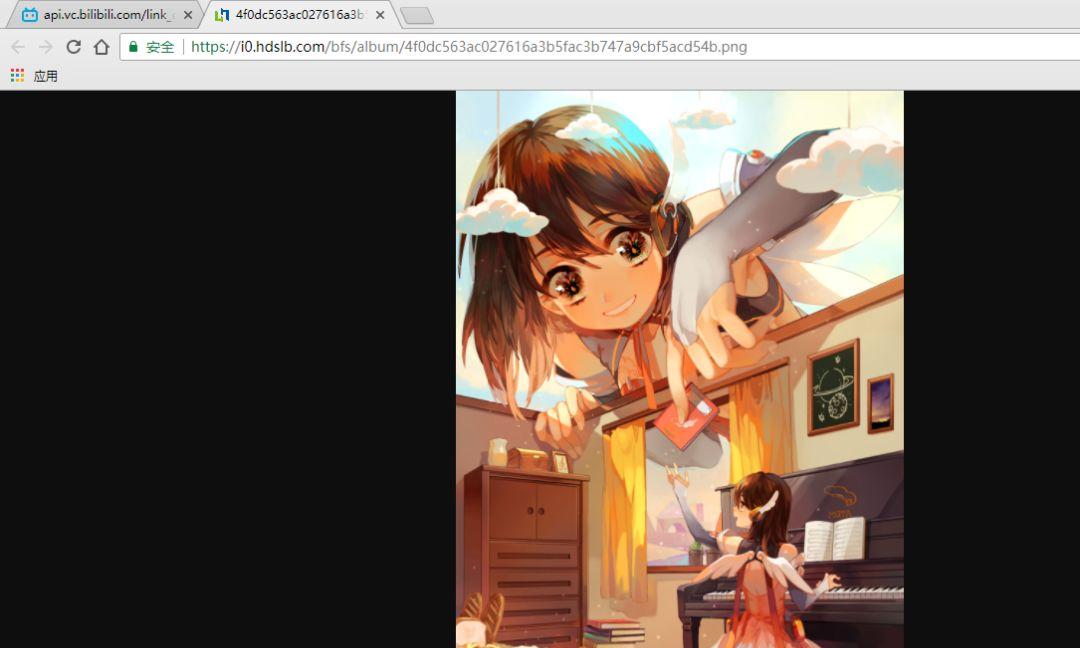
 精选热推刷新手机的时候,可以看到Fiddler界面出现了请求的链接返回的是json数据:
精选热推刷新手机的时候,可以看到Fiddler界面出现了请求的链接返回的是json数据:
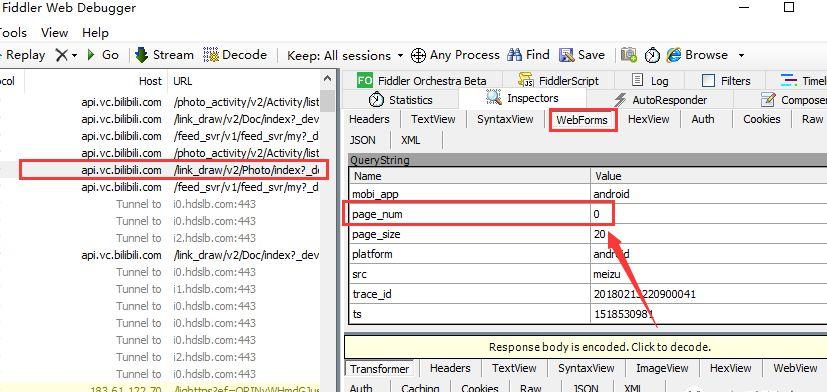
 图片接下来手机端往下拉,在Fiddler可以看到刷出了相似的请求,可以看到请求的参数里,page_num参数增加,这就是表示页码的参数:
图片接下来手机端往下拉,在Fiddler可以看到刷出了相似的请求,可以看到请求的参数里,page_num参数增加,这就是表示页码的参数:
 页码参数编写代码
页码参数编写代码
现在,图片的网址我们已经找出来了,接下来就可以编写代码下载图片了,这里我还是使用了Scrapy框架。
首先,还是新建项目:
scrapy startproject scrapy_bilibili
然后编写items.py定义存储字段:
import scrapyclass ScrapyBilibiliItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() image_urls = scrapy.Field() images = scrapy.Field() image_paths = scrapy.Field()
然后settings.py把ITEM_PIPELINES注释取消,还有增加IMAGES_STORE作为存储位置,还把USER_AGENT改成了Fiddler看到的值:
ITEM_PIPELINES = { ‘scrapy_bilibili.pipelines.ScrapyBilibiliPipeline’: 300,}IMAGES_STORE = ‘E:/scrapy_bilibili/images’USER_AGENT = ‘Mozilla/5.0 BiliDroid/5.22.1 (bbcallen@gmail.com)’
接下来是pipelines.py,这段代码改自官方文档:
import scrapyfrom scrapy.pipelines.images import ImagesPipelinefrom scrapy.exceptions import DropItemfrom scrapy.utils.project import get_project_settingsclass ScrapyBilibiliPipeline(ImagesPipeline): IMAGES_STORE = get_project_settings().get(‘IMAGES_STORE’) def get_media_requests(self, item, info): image_url = item[‘image_urls’] yield scrapy.Request(image_url) def item_completed(self, results, item, info): image_paths = [x[‘path’] for ok, x in results if ok] if not image_paths: raise DropItem(“Item contains no images”) item[‘image_paths’] = image_paths return item
最后在spiders文件夹里新建bilibili_spider.py放置爬虫的代码:
import jsonimport scrapyfrom scrapy_bilibili.items import ScrapyBilibiliItemclass BilibiliSpider(scrapy.Spider): name = ‘bilibili_spider’ allowed_domains = [‘api.vc.bilibili.com’] page_num = 0 start_urls = [‘http://api.vc.bilibili.com/link_draw/v2/Doc/…&page_num=’ str(page_num) ‘&page_size=20…’] # 链接太长我就不放完整了 def parse(self, response): datas = json.loads(response.text)[‘data’][‘items’] for data in datas: item = ScrapyBilibiliItem() for img in data[‘item’][‘pictures’]: item[‘image_urls’] = img[‘img_src’] yield item if self.page_num >= 10: return self.page_num = 1 yield scrapy.Request(‘http://api.vc.bilibili.com/link_draw/v2/Doc/…&page_num=’ str(self.page_num) ‘&page_size=20…’, callback = self.parse) # 链接也是不完整的运行代码
在项目的目录下执行以下命令,注意bilibili_spider是bilibili_spider.py里class的name:
scrapy crawl bilibili_spider
然后,等到运行完,就能看到结果了,图片是使用它们URL的SHA1 hash作为文件名的:
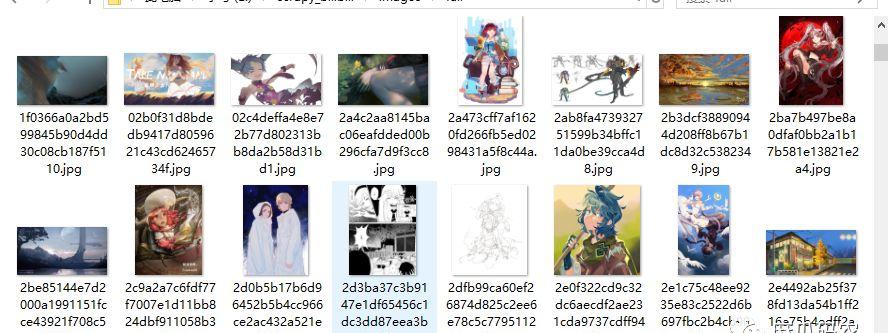 结果对了,这里要注意一个问题,运行的时候如果有挂代理,比如一些科学^_^上网的工具什么的就先关掉吧,不然可能会出现以下问题:
结果对了,这里要注意一个问题,运行的时候如果有挂代理,比如一些科学^_^上网的工具什么的就先关掉吧,不然可能会出现以下问题:
Connection to the other side was lost in a non-clean fashion: Connection lost.
到这里,我们的程序就完成了。再次祝大家新年快乐哈!!