多行转字符串
这个比较简单,用||或concat函数可以实现
select concat(id,username) str from app_user
select id||username str from app_user字符串转多列
实际上就是拆分字符串的问题,可以使用 substr、instr、regexp_substr函数方式
字符串转多行
使用union all函数等方式
wm_concat函数
首先让我们来看看这个神奇的函数wm_concat(列名),该函数可以把列值以”,”号分隔起来,并显示成一行,接下来上例子,看看这个神奇的函数如何应用准备测试数据
create table test(id number,name varchar2(20));
insert into test values(1,’a’);
insert into test values(1,’b’);
insert into test values(1,’c’);
insert into test values(2,’d’);
insert into test values(2,’e’);
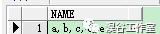
效果1 : 行转列 ,默认逗号隔开
select wm_concat(name) name from test;
效果2: 把结果里的逗号替换成”|”
select replace(wm_concat(name),’,’,’|’) from test;

效果3: 按ID分组合并nameselect id,wm_concat(name) name from test group by id;
 sql语句等同于下面的sql语句
sql语句等同于下面的sql语句
——– 适用范围:8i,9i,10g及以后版本 ( MAX DECODE )
select id, max(decode(rn, 1, name, null)) || max(decode(rn, 2, ‘,’ || name, null)) || max(decode(rn, 3, ‘,’ || name, null)) str
from (select id,name,row_number() over(partition by id order by name) as rn from test) t group by id order by 1;
——– 适用范围:8i,9i,10g及以后版本 ( ROW_NUMBER LEAD )
select id, str from (select id,row_number() over(partition by id order by name) as rn,name || lead(‘,’ || name, 1) over(partition by id order by name) ||
lead(‘,’ || name, 2) over(partition by id order by name) || lead(‘,’ || name, 3) over(partition by id order by name) as str from test) where rn = 1 order by 1;
——– 适用范围:10g及以后版本 ( MODEL )
select id, substr(str, 2) str from test model return updated rows partition by(id) dimension by(row_number() over(partition by id order by name) as rn)
measures (cast(name as varchar2(20)) as str) rules upsert iterate(3) until(presentv(str[iteration_number 2],1,0)=0) (str[0] = str[0] || ‘,’ || str[iteration_number 1]) order by 1;
——– 适用范围:8i,9i,10g及以后版本 ( MAX DECODE )
select t.id id,max(substr(sys_connect_by_path(t.name,’,’),2)) str from (select id, name, row_number() over(partition by id order by name) rn from test) t
start with rn = 1 connect by rn = prior rn 1 and id = prior id group by t.id;</span>懒人扩展用法:
案例: 我要写一个视图,类似”create or replace view as select
字段1,…字段50 from tablename” ,基表有50多个字段,要是靠手工写太麻烦了,有没有什么简便的方法?
当然有了,看我如果应用wm_concat来让这个需求变简单,假设我的APP_USER表中有(id,username,password,age)4个字段。查询结果如下
/** 这里的表名默认区分大小写 */
select ‘create or replace view as select ‘|| wm_concat(column_name) || ‘ from APP_USER’ sqlStr from user_tab_columns where table_name=’APP_USER’;

利用系统表方式查询
select * from user_tab_columns

Oracle 11g 行列互换 pivot 和 unpivot 说明
在Oracle 11g中,Oracle 又增加了2个查询:pivot(行转列) 和unpivot(列转行)
参考:http://blog.csdn.net/tianlesoftware/article/details/7060306、http://www.oracle.com/technetwork/cn/articles/11g-pivot-101924-zhs.html
google 一下,网上有一篇比较详细的文档:http://www.oracle-developer.net/display.php?id=506
pivot 列转行
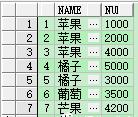
测试数据 (id,类型名称,销售数量),案例:根据水果的类型查询出一条数据显示出每种类型的销售数量。
create table demo(id int,name varchar(20),nums int); —- 创建表
insert into demo values(1, ‘苹果’, 1000);
insert into demo values(2, ‘苹果’, 2000);
insert into demo values(3, ‘苹果’, 4000);
insert into demo values(4, ‘橘子’, 5000);
insert into demo values(5, ‘橘子’, 3000);
insert into demo values(6, ‘葡萄’, 3500);
insert into demo values(7, ‘芒果’, 4200);
insert into demo values(8, ‘芒果’, 5500);
分组查询 (当然这是不符合查询一条数据的要求的)
select name, sum(nums) nums from demo group by name

行转列查询
select * from (select name, nums from demo) pivot (sum(nums) for name in (‘苹果’ 苹果, ‘橘子’, ‘葡萄’, ‘芒果’));

注意: pivot(聚合函数 for 列名 in(类型)) ,其中 in(‘’) 中可以指定别名,in中还可以指定子查询,比如 select distinct code from customers
当然也可以不使用pivot函数,等同于下列语句,只是代码比较长,容易理解
select * from (select sum(nums) 苹果 from demo where name=’苹果’),(select sum(nums) 橘子 from demo where name=’橘子’),
(select sum(nums) 葡萄 from demo where name=’葡萄’),(select sum(nums) 芒果 from demo where name=’芒果’); unpivot 行转列
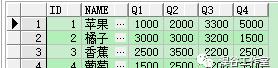
顾名思义就是将多列转换成1列中去案例:现在有一个水果表,记录了4个季度的销售数量,现在要将每种水果的每个季度的销售情况用多行数据展示。
创建表和数据
create table Fruit(id int,name varchar(20), Q1 int, Q2 int, Q3 int, Q4 int);
insert into Fruit values(1,’苹果’,1000,2000,3300,5000);
insert into Fruit values(2,’橘子’,3000,3000,3200,1500);
insert into Fruit values(3,’香蕉’,2500,3500,2200,2500);
insert into Fruit values(4,’葡萄’,1500,2500,1200,3500);
select * from Fruit
列转行查询
select id , name, jidu, xiaoshou from Fruit unpivot (xiaoshou for jidu in (q1, q2, q3, q4) )
注意: unpivot没有聚合函数,xiaoshou、jidu字段也是临时的变量
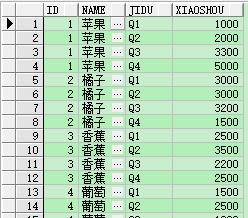
同样不使用unpivot也可以实现同样的效果,只是sql语句会很长,而且执行速度效率也没有前者高
select id, name ,’Q1′ jidu, (select q1 from fruit where id=f.id) xiaoshou from Fruit f
union
select id, name ,’Q2′ jidu, (select q2 from fruit where id=f.id) xiaoshou from Fruit f
union
select id, name ,’Q3′ jidu, (select q3 from fruit where id=f.id) xiaoshou from Fruit f
union
select id, name ,’Q4′ jidu, (select q4 from fruit where id=f.id) xiaoshou from Fruit f
XML类型
上述pivot列转行示例中,你已经知道了需要查询的类型有哪些,用in()的方式包含,假设如果您不知道都有哪些值,您怎么构建查询呢?
pivot 操作中的另一个子句 XML 可用于解决此问题。该子句允许您以 XML 格式创建执行了 pivot 操作的输出,在此输出中,您可以指定一个特殊的子句 ANY 而非文字值
示例如下:
select * from (
select name, nums as “Purchase Frequency”
from demo t
)
pivot xml (
sum(nums) for name in (any)
)
 如您所见,列 NAME_XML 是 XMLTYPE,其中根元素是 <PivotSet>。每个值以名称-值元素对的形式表示。您可以使用任何 XML 分析器中的输出生成更有用的输出。
如您所见,列 NAME_XML 是 XMLTYPE,其中根元素是 <PivotSet>。每个值以名称-值元素对的形式表示。您可以使用任何 XML 分析器中的输出生成更有用的输出。

结论
Pivot 为 SQL 语言增添了一个非常重要且实用的功能。您可以使用 pivot 函数针对任何关系表创建一个交叉表报表,而不必编写包含大量 decode 函数的令人费解的、不直观的代码。同样,您可以使用 unpivot 操作转换任何交叉表报表,以常规关系表的形式对其进行存储。Pivot 可以生成常规文本或 XML 格式的输出。如果是 XML 格式的输出,您不必指定 pivot 操作需要搜索的值域。