“实测训练速度比i7-8700提升十倍以上。”
前段时间自己在研究机器学习对硬件安全电路的建模攻击。随着训练集的不断增加,实验室提供的那台Think Station愈发难担大任,训练 10M 的数据模型要好几天的时间。而购买专用的训练卡或服务器对于自己这种偶尔才用几次的人又有点浪费,所以决定尝试一下大厂提供的GPU加速型云服务器。如果感觉OK,就和老板商量一下,以后在云服务器上训练。
01
—
GPU弹性云服务器配置
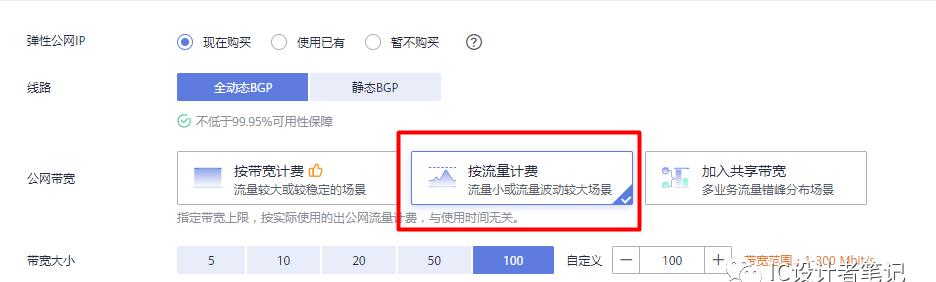
华为云控制台界面如下图所示:
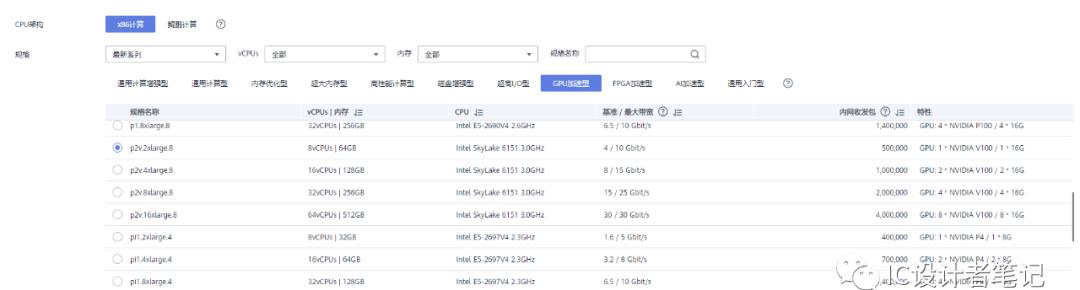
自己购买的是GPU加速型-计算加速P系列p2v型弹性云服务器。注意购买GPU弹性云服务器时需要选择上海二节点,其它节点可能没有p2v资源。如果自己的账户中没显示上海二节点,可通过提交工单的方式开通:
控制台->工单->新建工单->配额类->配额申请->新建工单;选择任意区域,并在问题描述中填写“申请开通上海二节点资源”。也可以直接联系客服快速申请开通。
初次尝试,选择了最低配置,即只有一张NVIDIA 特斯拉 V100 加速卡,具体配置如下图。计费方式为按需计费。系统镜像刚开始选择的CentOS, 后来TensorFlow一直安装不成功,最后又换成了Ubuntu 16.04。
网络配置选的“按流量计费”,其余均为默认。
02
—
安装TensorFlow
华为提供的系统镜像中只安装了CUDA 9.2和Python 2.7,Cudnn和TensorFlow需要自己安装。由于CUDA和Python版本比较落后,而不同版本的TensorFlow对Python、CUDA的版本要求均不相同(具体见下图),导致刚开始踩了各种坑:
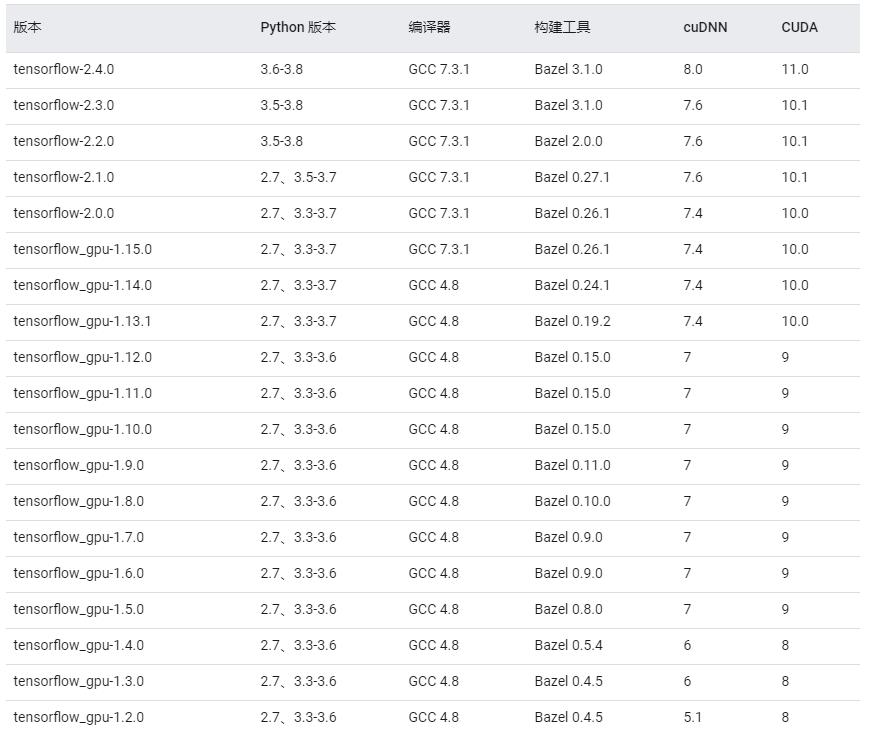
通过pip方式安装TensorFlow时,最后会提示Python版本落后(≥3.7),具体原因未知,更新Python版本后,又发现pip方式无法获取与CUDA 9.2相匹配的TensorFlow安装包。经过多个小时的折腾,自己最终决定,升级CUDA版本至10.1,并重新安装显卡驱动(低版本驱动无法支持高版本CUDA,具体对应关系如下图)。

为避免大家少走弯路,自己整理安装过程如下,仅供参考。
升级Python至3.7
可通过编译源码的方式升级,步骤如下:
mkdir /usr/local/python37cd /usr/local/python37#下载Python源码wget https://www.python.org/ftp/python/3.7.4/Python-3.7.4.tgztar -xzvf Python-3.7.4.tgzcd Python-3.7.4#执行./configure配置构建文件./configure –enable-optimizations# 编译并安装make && sudo make install# 添加python3的软链接sudo ln -s /usr/local/bin/python3.7 /usr/bin/python3.7# 备份并替换原有链接mv /usr/bin/python /usr/bin/python.bak sudo ln -s /usr/local/bin/python3.7 /usr/bin/python# 添加 pip3 的软链接sudo ln -s /usr/local/bin/pip3.7 /usr/bin/pip3.7mv /usr/bin/pip /usr/bin/pip.baksudo ln -s /usr/local/bin/pip3.7 /usr/bin/pip# 检查Python版本并确认已经安装成功python -V
升级CUDA至10.1
具体命令如下:
#卸载NVIDIA驱动sudo /usr/bin/nvidia-uninstall#重启sudo reboot#创建安装包下载目录mkdir ~/downloadcd ~/download#下载安装包并安装wget https://developer.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda_10.1.105_418.39_linux.runsudo sh cuda_10.1.105_418.39_linux.run
在弹出的界面中选下一步或继续,直至安装完成。
创建软连接,并添加路径至 ~/.bashrc
sudo ln -s /usr/local/cuda-10.1/ /usr/local/cudavi ~/.bashrc
在文件末尾添加如下内容
export PATH=/usr/local/cuda/bin${PATH: :${PATH}}export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH: :${LD_LIBRARY_PATH}}export CUDA_HOME=/usr/local/cuda
运行如下命令,检查CUDA是否安装成功。
nvcc –version

安装cudnn
将下载的安装包上传至云服务器,并切换至安装包所在目录运行如下命令安装:
dpkg -i libcudnn7_7.6.4.38-1 cuda10.1_amd64.deb
安装过程如下图:

安装TensoFlow 2.3.0
万事俱备,只欠东风。下面我们就可以用pip命令安全TensorFlow了,本文安装的 TensorFlow 2.3.0,版本号很重要,必须与CUDA和cudnn版本对应,否则TensorFlow无法工作。
安装之前,先将pip下载源修改为国内镜像,如 豆瓣,清华,阿里云等,实测豆瓣比较稳定,推荐。
豆瓣:https://pypi.douban.com/simple
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学:https://pypi.mirrors.ustc.edu.cn/simple/
清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/
具体修改方法如下:
在当前用户根目录下新建 .pip 目录,并创建pip.conf 文件
mkdir ~/.pip/cd ~/.pip/vi pip.conf
pip.conf 文件文件内容如下,以豆瓣镜像为例
[global]index-url = https://pypi.douban.com/simple[install]trusted-host = https://pypi.douban.com
修改完成之后,即可使用如下命令安装 TensorFlow, 如果安装失败,可尝试更换镜像源。
pip install –upgrade tensorflow==2.3.0
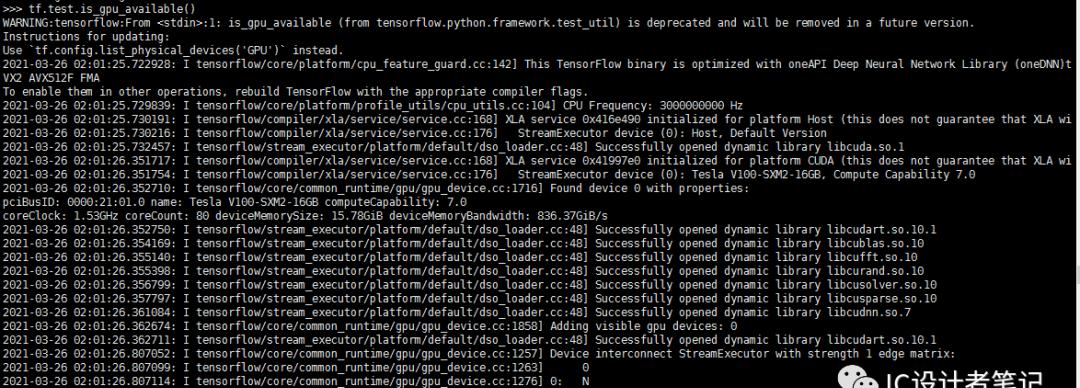
安装完成后,可用如下命令测试TensorFlow GPU是否可用
python
>>> import tensorflow as tf
>>> tf.test.is_gpu_available()
如下图所示,如果最终输出结果为 True, 则证明安装成功。否则需要检查CUDA和cudnn的版本是否正确。
注意:因为本文安装的TensorFlow 2.3.0版本,如果之前的代码基于 TensorFlow 1.0,则会出现很多库函数无法识别的错误,例如:
ModuleNotFoundError: No module named ‘tensorflow.compat.v1’
我们可以使用TensorFlow自带的转换工具( tf_upgrage_v2)将 1.0版本的代码转为 2.0版本。可使用如下命令查看使用方法:
tf_upgrage_v2 -h
03
—
性能测试
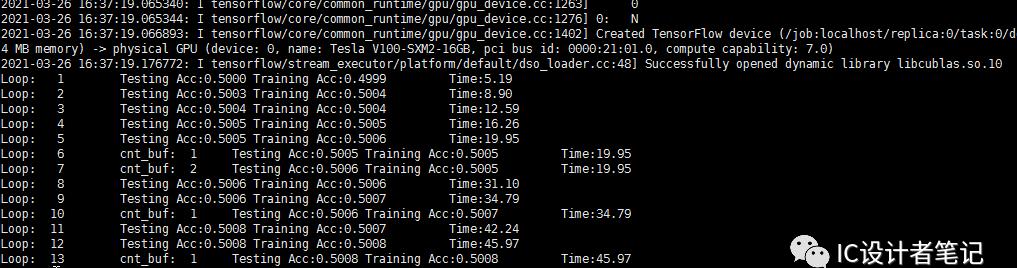
为了测试云服务器的训练速度,我们可以用相同的数据和神经网络与本地电脑进行对比训练。下图分别是在本地电脑和云服务器上的训练时间对比,神经网络结构为 64x128x128x128x2的全链接网络,训练集为 10 Million, 测试集为 1 Million。可以看到,进行单次迭代云服务器的训练时间仅为本地电脑的十分之一左右。
本地电脑训练时间消耗(Think Station : i7-8700 CPU, 64GB RAM):

弹性云服务训练时间消耗:
04
—
部分参考文献
使用pip安装TensorFlow
https://www.tensorflow.org/install/pip?hl=zh_cn
完美解决由于CUDA版本不匹配造成的各种坑
https://baijiahao.baidu.com/s?id=1663920145053509733&wfr=spider&for=pc
Python安装与升级
https://blog.csdn.net/weixin_41599858/article/details/101795427/details/101795427
将pip源更换到国内镜像
https://blog.csdn.net/sinat_21591675/article/details/82770360
Ubuntu16.04下安装cuda和cudnn的三种方法
https://blog.csdn.net/wanzhen4330/article/details/81699769