赠送书籍:《白帽子讲 Web 扫描》
在渗透测试中,扫描器必不可少,毕竟目标很多,需要检测点也很多,不可能全部手工搞定的,所以很多渗透者都有自己的自动化工具或者脚本,这里就为大家分享一款由我自己开发的一个自动化全网漏洞扫描工具。
扫描原理
由 Python Mysql 打造的扫描器,主要目的是实现自动化采集网站,扫描网站的常规性漏洞。希望做到挂机就能实现自动化发掘敏感情报,亦或是发现网站的漏洞或者隐藏可利用的漏洞
软件工程的核心功能就必须满足以下的需求。
1、能无限爬行采集互联网上存活的网址链接
2、能对采集到的链接进行是否存活扫描验证
3、Mysql数据库和服务器的负载均衡处理
漏洞的扫描验证功能。
1、备份文件扫描功能
2、SVN/GIT/源码泄漏扫描功能,其中包括 webinfo 信息扫描
4、SQL 注入漏洞的自动检测功能
5、使用 Struts2 框架的网站验证功能(居心叵测)
6、扫描网站 IP 并且扫描危险端口功能
7、CMS 类型识别(主要功能)
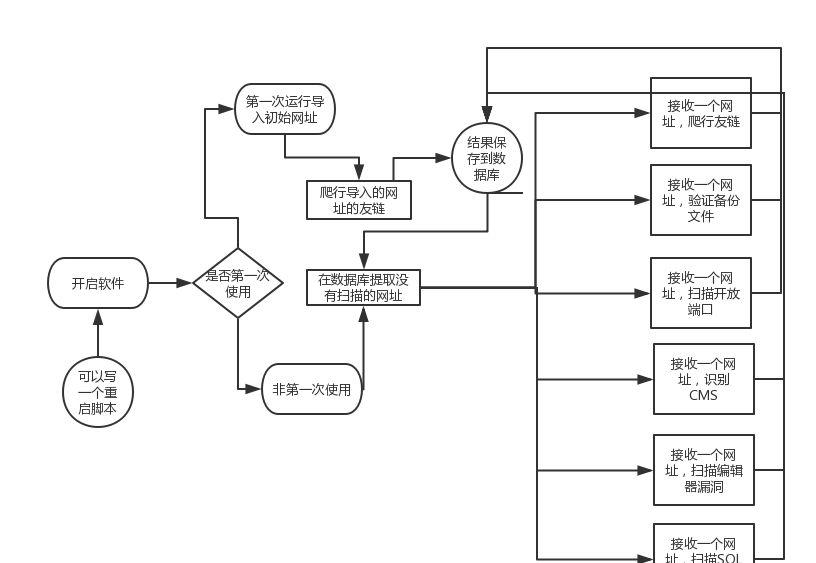
软件流程
结果展示
如图展示的都是挂机扫描到的备份文件,敏感信息泄漏,注入,cms 类型识别,st2 框架,端口开放等等,挂机刷洞,基本上只要漏洞报告写得详细一点,勤快多写点,都可以通过审核,要刷洞小意思,刷排名之类的都不在话下。
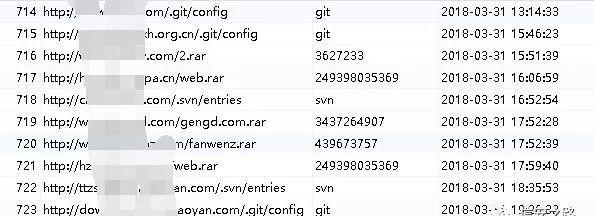

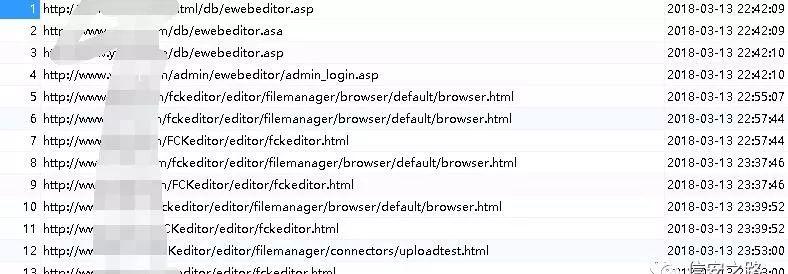

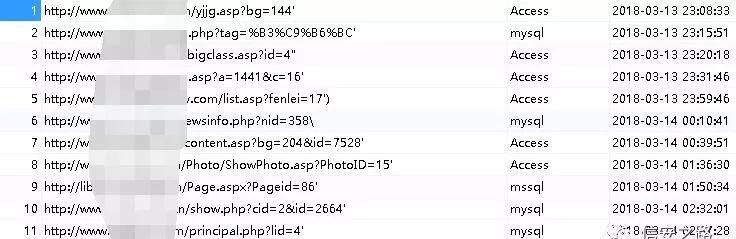
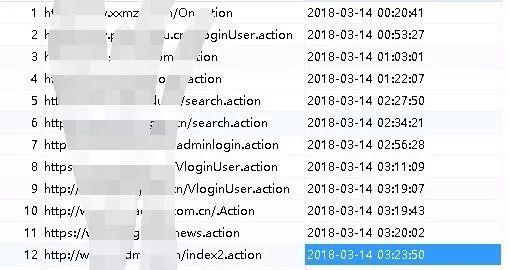
用户交互模式
需要使用 Mysql 数据库就无法避免数据库配置问题,首先是存储软件采集到的漏洞信息的数据库,可以自己写一张数据库的结构的语句,然后让用户自己执行这份 SQL 文件,创建好这个数据库。
为了避免每个人爬行到的数据重复,我的想法是首先让用户采集一些网址作为初始网址,然后基于这些网址开始无限爬行。如果是第一次运行的话应该提示导入初始网址,如果第二次运行呢?是不是还要继续导入初始网址然后继续爬行?那样就太没有艺术性了。我的办法是在上文提到的 Config.ini 文件里面有一个配置项,如果第一次运行的话会写入第一次运行并保存,然后以后每次运行前都先检测是不是第一次运行要不要导入之类的。(这里可以引伸出来,如果要无限爬行的话会出现一些内存垃圾没有及时回收,然后时间久后整个扫描都会变慢,那么就需要添加自动重启功能。)
采集到了数据肯定要查看和保存利用,因为数据都在数据库里面,我想过另写一个软件,专门用来导出数据,方便一些不懂 Mysql 的用户使用。但是后来想想又觉得有些多余,仿佛有点侮辱在座的各位智商的意思。那么来总结一下思路,先写好两个文件=> Config.ini (数据库配置文件以及扫描器配置文件) &database.sql (数据库安装语句) => 然后用户自己先采集一些网站,保存在当前目录下的一个 txt 文件里面=>配置好相关的文件和环境后,开启扫描程序。
工程构架
要实现的功能有点多,所以为了以后方便维护就应该把每个功能封闭在一个函数里面,这个函数接受一个参数 URL,对传递进来的参数进行验证,验证过程中也有许多要注意的地方,比如无限采集网站函数中,对采集到的网站先访问一次,看看是不是存活的,避免把不能访问的网站添加进数据库,浪费时间和资源。检验存活的方式应该用 head 头访问方式,判断返回的状态码。
还有判断 CMS 类别的话,不应该只限于 CMS 指纹方式扫描,还有在页面寻找关键词,访问 robots.txt 判断 CMS 类别。SQL 扫描我一开始是直接爬行页面寻找可疑的注入点,然后加上单引号括号反斜杠之类,匹配数据库报错语句,虽然流程没错,但是在工程上不是很妥当,后来在 098 版本中,在数据库里面新建表,专门储存爬行到的注入注入链接,如果觉得扫描器自带的监测注入方法不全面,同样可以把这些爬行到的链接导出来,然后用 sqlmap -m 批量检测注入点。还有很多要注意的此处不表。
提高容错率与优化
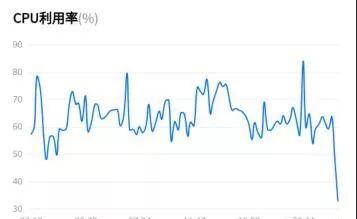
一般来说这种全网性质的扫描,基本上没有人舍得用自己的宝贝电脑挂机跑,都是丢在服务器。我的服务器是一台腾讯云 1C1M2G 的主机,运行 095 版本的时候,基本上开三个线程 CPU 保持在 40% 左右,还行。但是运行 098 版本的时候,同样的配置同样的线程,CPU 持续 90% 左右。服务器负载 太大,就不能在运行别的一些服务应用,于是我在程序中做了线程同步处理,还有一些地方做了优化,CPU 使用率下降到 20-40 之间,但是带来的后果就是整个扫描速度变慢,于是我试着开了 5 个线程,CPU 基本上稳定 80%。加上自动重启后,自定义重启时间,基本上控制好在 40-70 之间,还是需要进一步优化。
代码功能补充
比如在扫描备份文件的时候,办法是导入备份文件的字典。但是有一些网站的备份文件命名方式是以域名为名字。比如
www.langzi.fun/langzi.rar
这样的备份文件,这里就需要切割域名拼接成字典,当然后缀也不能只限于 rar,还有 zip,bak,sql,tar.gz,txt 等等…检测 CMS 类别用到了三种方法来逐一检测,如果第一种方法成功识别 CMS 类别后就不再继续执行后面的两个方法,这样做一来是节省资源和时间,二来是数据浪费,你只需要知道这个网站用的 CMS 类别就可以了,没必要知道有多少种方式检测到的。
Yoland_Liu 敏感情报扫描器
某天无意和佩瑶聊起这个话题,见她有兴趣我就详说了这个扫描器的核心功能和工程设计思维,但是我前面的构架代码写的太难看(这就是为什么我迟迟不敢开源的原因/捂脸)自己都不想去维护。接下来整个项目都交给她,基于核心思想上,写出了新版本,并且添加了新的功能。为后来我继续更新的 0.98 版本提供了更加完善的构架基础。为了感谢刘老师作出的杰出贡献,所以扫描器命名 Yoland_Liu 危险情报采集扫描器。
优点与缺点
优点:数据库数据重复处理,CMS 验证方式新增为 3 种,包括识别页面关键字,robots.txt 文件关键词识别,另外添加使用 ST2 框架网站的扫描,数据库优化,原始代码重写,更加稳定方便维护。
缺点:虽然整体的框架优化好了,但是却没有做内存垃圾回收,线程的方面没有控制好,导致如果一直挂着的话后面速度会越来越慢。因为专业性的问题,还有一些漏洞扫描功能并没有添加进去,所以造轮子这个活就落在我身上,后面更新版本都是基于0.95版本上加上其他漏洞扫描功能。
补充说明
这个 0.95 版本虽然在内存上没有做好优化,但是却可以通过加上自动重启功能来解决问题,并且与后来我写的 0.98 版本对比来说,0.95 速度更快(因为需要扫描的项目功能比较少),更加稳定( 0.98 版本虽然功能添加很多,但是对服务器负载很重,虽然我在 0.98 版本中做了内存优化处理,并且也添加了自动重启功能,但是最多也只能开 5 个线程 (CPU:80 %),最少开 3 个线程 (CPU:40 %)),要注意的是,开启多线程最少要开 3 个。
https://pan.baidu.com/s/1Y5nBa-N9rHbZUhJORh41ZQ
密码:frwp (解压密码默认 lang),此版本首发信安之路
使用说明
配置文件
当你解压文件后要注意下面这几个文件,这些文件关系到数据库配置,软件个性化扫描,线程设置,初始扫描导入网站等等。

使用方法
1、首先安装好 mysql 数据库
2、把 mysql.sql 文件执行,然后刷新以下会发现多了一个数据库
3、配置 Config.ini,上面部分是数据库配置相关设置,下面是软件扫描功能设置。
为了更加多元化的使用,你可以选择性的使用某些功能,具体看参数是 0 还是 1,这里 0 就是关闭的意思,1 就是开启的意思,如果你想只检测 cms,就设置 cmsscan=1,另外 thread_s 对应的是线程数,new_start 是检测是否第一次扫描,默认是 1,设置 1 的话,每次打开都会提示让你导入一些网站作为初始网站。程序检测到加载初始网站后,会自动把这个参数改成 0。
结语
在这款扫描器诞生前一年,也就是 17 年 2 月份的时候,我也写过一款失败的扫描器 (Iosmosis Scan),说来现在最新的 0.98 版本依稀可以看到 ios scan 的一点影子。不可否认 ios scan 是失败的,但是为现在的扫描器鉴定了大部分框架蓝图,比如备份文件和源码泄漏功能都是直接从那里继承过来的。ios scan 还集成了数据库,ftp,telnet 等爆破功能…说来感觉还是有点呆。
在未来的日子里会不断更新添加新的功能,遵循此扫描器的核心思想>>>>无限永久自动爬行。无限自动检测就是这款扫描器的灵魂,就像一只孜孜不倦的蜘蛛,把网织得越来越大。扫描器会一直免费更新下去,敬请期待。