不少小伙伴在写SQL和调优过程中,都遇到过和分页(Paging Through Data)有关的问题。那么就让我们聊一聊数据库中的SQL的分页技术,这一篇主要专注Oracle数据库分页,下一篇我们分析下MySQL和PostgreSQL的分页。
Oracle的传统分页技术
其实,Oracle数据库的分页技术核心来自于SQL语法中一个分支叫做Top-N query,也就是从结果集中找到前N行的查询方法。
我们先看一下最传统,也是大家使用最多的分页SQL写法,以及里面的Top-N query语法,这个分页SQL实现的需求是:将emp表按照ename(员工姓名)进行正排序,对于结果集分为每页5行数据,取出第2页,也就是第6行到第10行数据。
表结构如下(emp表是一张员工表,其中有一列名为ename,表示员工的姓名):
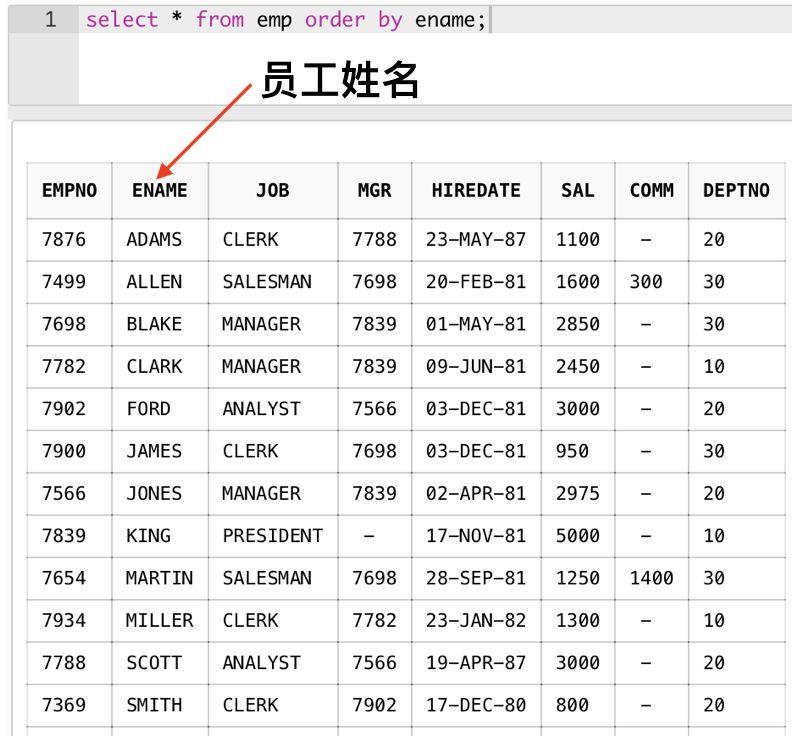
我们采用最多的方法是利用Oracle数据表中的一个伪列rownum,rownum帮助我们标示结果集中每一行的顺序编号。
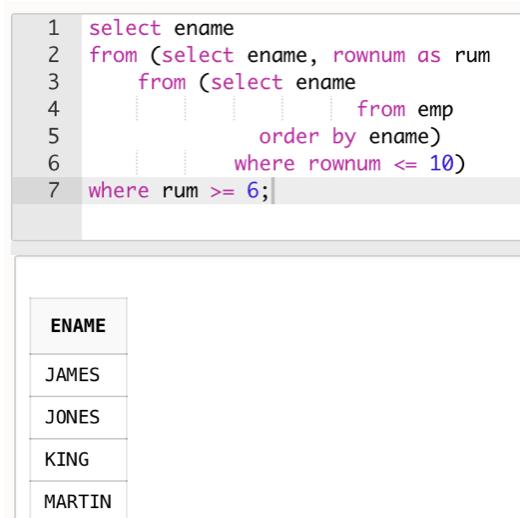
select ename
from (select ename, rownum as rum
from (select ename
from emp
order by ename)
where rownum <= 10)
where rum >= 6;
查询结果如下:
之前就有小伙伴问过我,为什么分页的语法要用到两次嵌套子查询,看着有些麻烦!那么下面就来分析一下这两次嵌套子查询的作用和必要性,我将SQL的流程图画在下面:
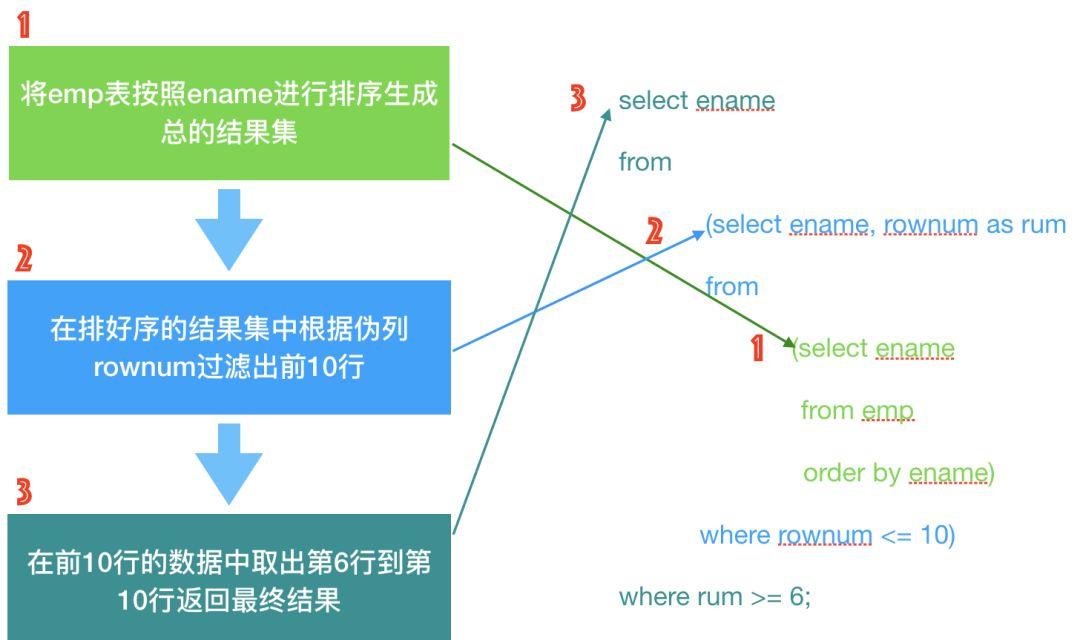
对,你没看错!这个就是传统Oracle数据库中最普适的分页方法,你可能会觉得用到两次子查询性能上不够优化,这个问题我们放在文章后面讨论,因为它恰恰证明了这种写法是Oracle推荐的好写法。
下面先解释一下为什么要用到两次嵌套子查询,我们逆向思考一下,首先,将1层查询与2层查询合并行不行?也就是写成:
select ename from emp where rownum <=10 order by ename;
大家从结果可以看出:
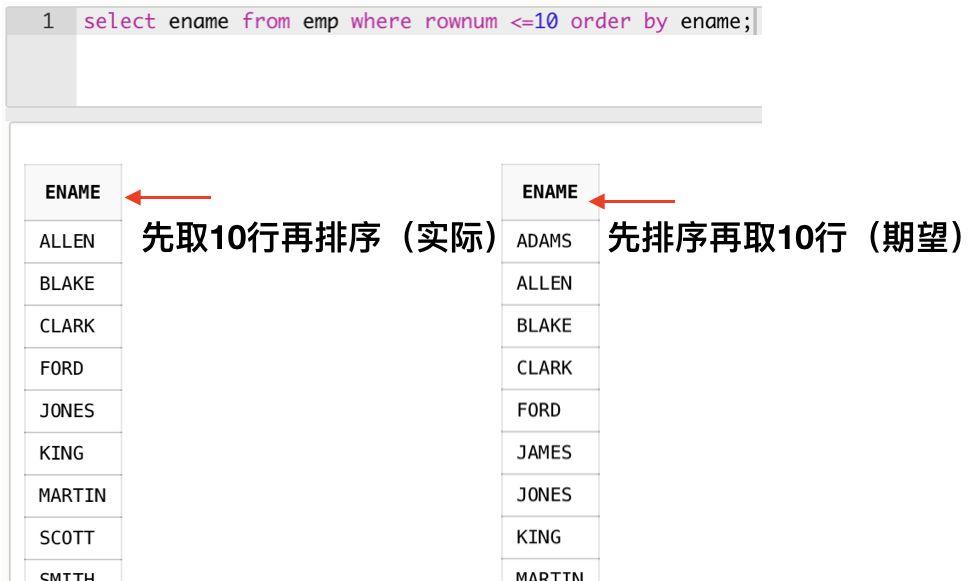
因为SQL语句在执行的时候,会将where子句先于order by来执行,所以我们无法获得期待的结果。看来,第1层和第2层是不可能合并的。
其次,我们看看第2层查询和第3层查询是不是可以合并。
select ename,rownum as rum
from (select ename
from emp
order by ename)
where rownum <= 10 androwum >= 6;
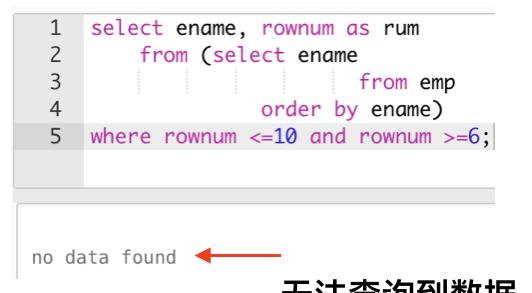
结果是没有任何数据,说明也不可以,因为伪列rownum在where子句中只能用小于(<)或者小于等于(<=),而不可以用大于(>),大于等于(>=)和等于(=)。
如此说来,在Oracle中如果要完成分页,也只能用这种嵌套两个子查询的写法了。相比MySQL和PostgreSQL数据库在SQL语法中支持LIMIT OFFSET子句的做法,Oracle的传统分页显得不是非常友好。
Oracle 12c后的分页语法
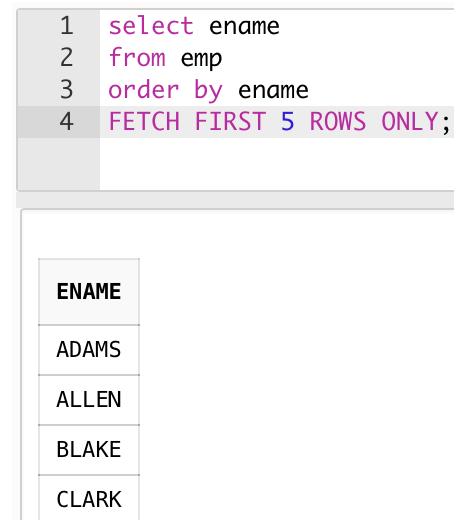
如果你操作的数据库是Oracle 12c以后的版本,Oracle数据库提供给了新的Top-N query方法,比如,我想取到emp表中的前5行,并且按照ename排序,可以写成:
select ename
from emp
order by ename
FETCH FIRST 5 ROWS ONLY;
想取emp表中按ename排序的前20%数据,可以写成:
select ename
from emp
order by ename
FETCH FIRST 20 PERCENT ROWS ONLY;
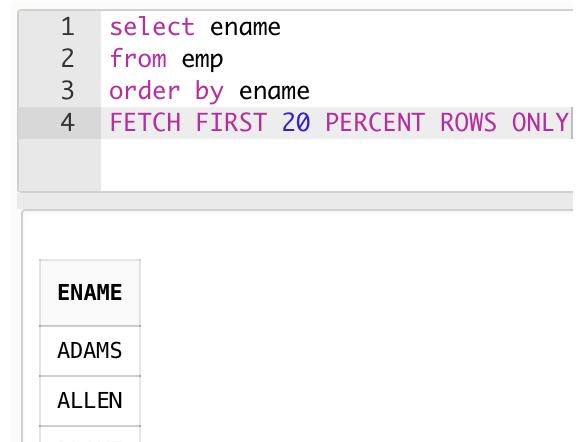
没错,就是FETCH FIRST N(PERCENT)ROWS ONLY子句,帮助我们可以轻松取到前N(TOP N)行数据。并且完全规避了使用伪列rownum会遇到的,where子句先于order by排序的尴尬,因为FETCH FIRST N(PERCENT)ROWS ONLY是在order by排序的后面才执行的。
那么,对于分页我们怎么解决呢?
很简单,同样的需求,将emp表按照ename(员工姓名)进行正排序,对于结果集分为每页5行数据,取出第2页,也就是第6行到第10行数据,我们的新SQL就会是:
select ename
from emp
order by ename
OFFSET 5 ROWS FETCH NEXT 5 ROWS ONLY;
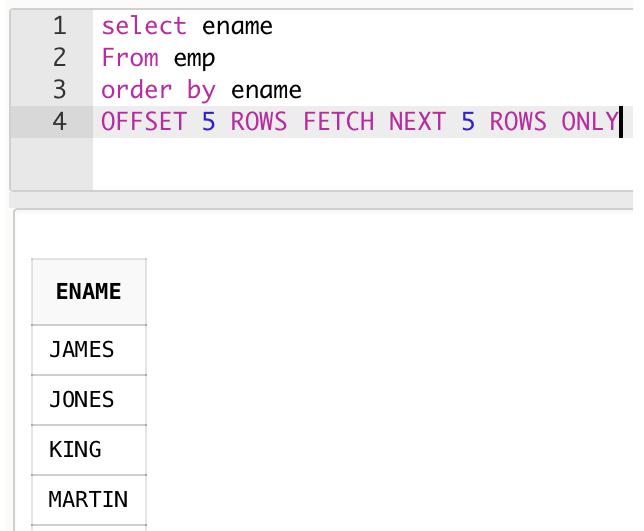
OFFSET 5 ROWS FETCH NEXT 5 ROWS ONLY这个子句代表的意思就是从结果集的第5行的下一行开始,连续取5行数据(也就是6~10行)。
所以说,如果你的数据库是Oracle12c,那么分页操作再也不会是很复杂的SQL了,好了,下面让我们来看看性能吧。
分页的性能
这里可以负责和遗憾地告诉大家,新的分页SQL写法:
select ename
from emp
order by ename
OFFSET 5 ROWS FETCH NEXT 5 ROWS ONLY;
在性能上,相比老的写法:
select ename
from (select ename, rownum as rum
from (select ename
from emp
order by ename)
where rownum <= 10)
where rum >= 6;
是没有区别的。
这里我做了一个实验,用10053等待事件跟踪SQL的执行时会发现:OFFSET 5 ROWS FETCH NEXT 5 ROWS ONLY会被改写为传统的rownum的top-n query写法。所以,OFFSET 5 ROWS FETCH NEXT 5 ROWS ONLY子句其实只是一个语法糖(syntax candy)而已。如果小伙伴不了解10053 trace SQL,就理解为两种方法最终性能一样就可以了,因为新的SQL写法在SQL执行时候会被转化为传统写法。下面几幅图,是10053 trace的过程。
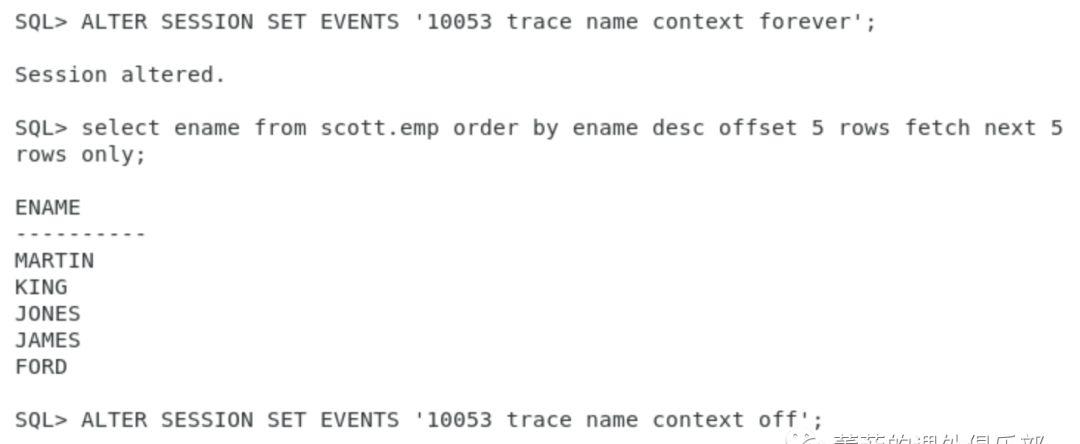
10053 trace中的转换结果:
Final query after transformations:******* UNPARSED QUERY IS *******
SELECT “from$_subquery$_002″.”ENAME” “ENAME” FROM (SELECT “EMP”.”ENAME” “ENAME”,”EMP”.”ENAME” “rowlimit_$_0”,ROW_NUMBER() OVER ( ORDER BY “EMP”.”ENAME” DESC )”rowlimit_$$_rownumber” FROM “SCOTT”.”EMP” “EMP” WHERE 5<10) “from$_subquery$_002” WHERE “from$_subquery$_002”.”rowlimit_$$_rownumber”<=10 AND “from$_subquery$_002″.”rowlimit_$$_rownumber”>5 ORDER BY “from$_subquery$_002”.”rowlimit_$_0″ DESC
下面我们看另一个性能问题,那就是传统的Top-N Query方法是不是真的很差呢。其实并不是这样的,我们从传统rownum方法的执行计划中发现,Oracle优化器实际上是将外层查询的谓词条件(predicates)下推(push down)到里层的查询中去了,请看:
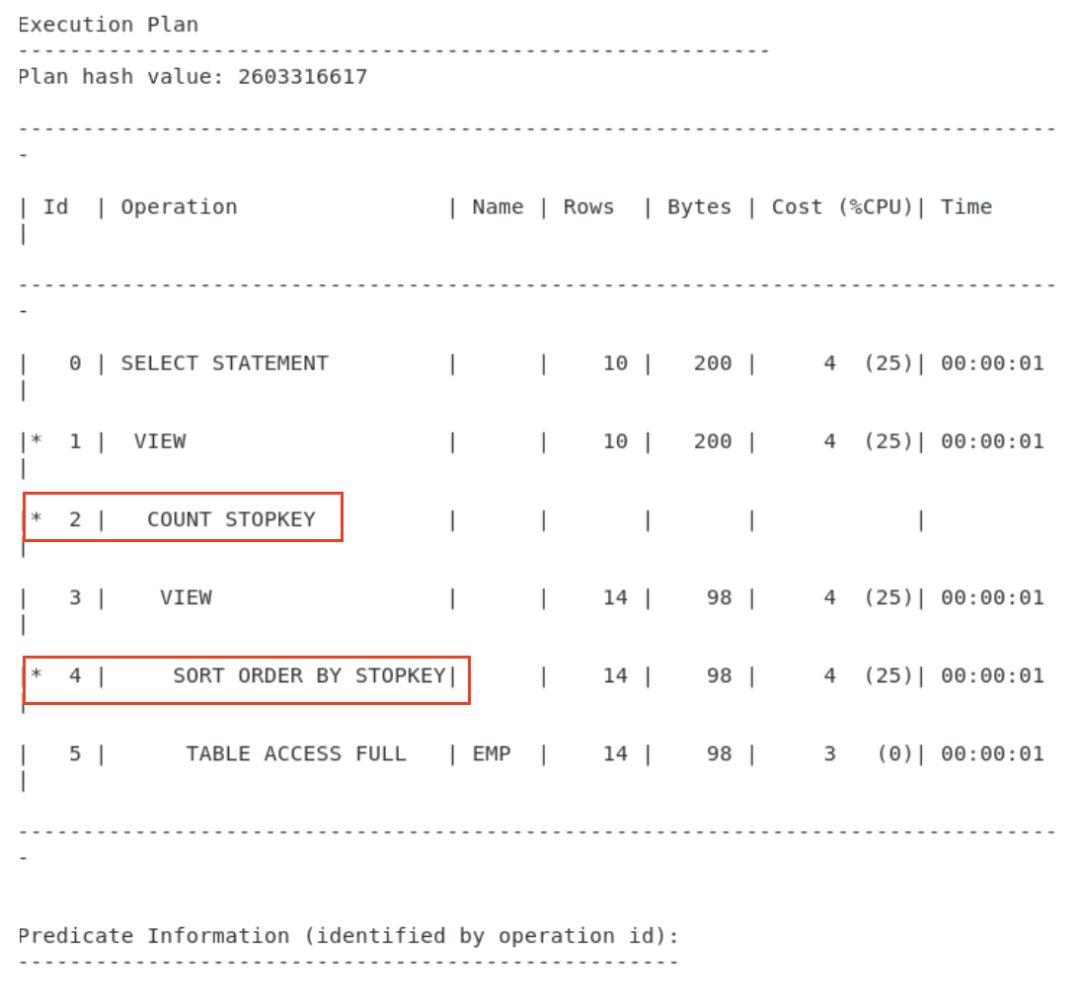
这样一来,相当于是嵌套的子查询被改写为了单层过滤,所以效率相对不差。
从这个角度来看,Oracle数据库的优化器实际是对分页技术的核心Top-N query做了优化的,而Oracle12c版本之后推出的OFFSET n ROWS FETCH NEXT m ROWS ONLY写法也只不过是为了让SQL的书写和阅读更加便利,在性能上似乎已经到了优化器所能达到的瓶颈了。
总结一下,当大家面对Oracle数据库上的SQL分页操作时候,请了解:
如果你用的是Oracle12c数据库,那么OFFSET n ROWS FETCH NEXT m ROWS ONLY;可以让你的SQL更加简明。如果是Oracle12c之前的版本,那么我们就用传统的rownum嵌套的写法。
性能上,Oracle数据库本身已经对于分页技术的核心Top-N query做了优化,我们没有必要再去绞尽脑汁想如何写出更优的分页SQL了。
要知道,任何SQL的优化是有极限的,那就是SQL语句的执行时间是和你所要得到的结果集大小成正比的。当我们要排序和分页的表确实很大的时候,可能只靠SQL语句的优化就不够了。必须辅助相应的设计修改,比如分页索引的建立,限制用户分页行数,数据分区或者分片和数据缓存等技术来用空间换时间了。
关于海量大数据的查询优化技术,其实我们也可以用SQL来搞定,我会另总结一个大SQL的专辑,跟大家一起讨论海量数据之后的SQL技术。、 下一篇文章,我们继续看看在语法中支持limit offset写法的MySQL和PostgreSQL数据库如何处理分页。