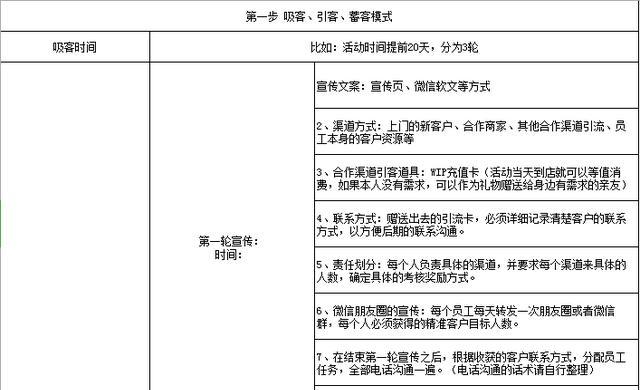
Oracle数据库的安装
我安装的Oracle数据库版本为Oracle Database 12c Release 2
具体安装教程可以参考 百度经验
操作系统为安装在虚拟机里面的Windows Server 2019 DataCenter
客户端我是用的是PLSQL Developer 13。官网 激活码
Oracle体系结构数据库
Oracle 数据库是数据的物理存储。其实 Oracle 数据库的概念和其它数据库不一样,这里的数据库是一个操作系统 只有一个库。可以看作是 Oracle 就只有一个大数据库。
实例
一个 Oracle 实例(Oracle Instance)有一系列的后台进程(Backguound Processes)和内存结构 (Memory Structures)组成。一个数据库可以有 n 个实例。
12c 版本已经能一个实例有多个数据库了。
用户
用户是在实例下建立的。不同实例可以建相同名字的用户。
在Oracle数据库中用户是管理表的基本单位,对应MySQL中,某某库拥有几张表,而在Oracle中为:某某用户有几张表。
表空间
表空间是 Oracle 对物理数据库上相关数据文件(ORA 或者 DBF 文件)的逻辑映射。一个数 据库在逻辑上被划分成一到若干个表空间,每个表空间包含了在逻辑上相关联的一组结构。每 个数据库至少有一个表空间(称之为 system 表空间)。
每个表空间由同一磁盘上的一个或多个文件组成,这些文件叫数据文件(datafile)。一个数据文件 只能属于一个表空间。
数据文件(dbf、ora)
数据文件是数据库的物理存储单位。数据库的数据是存储在表空间中的,真正是在某一个 或者多个数据文件中。而一个表空间可以由一个或多个数据文件组成,一个数据文件只能属于 一个表空间。一旦数据文件被加入到某个表空间后,就不能删除这个文件,如果要删除某个数 据文件,只能删除其所属于的表空间才行。
Oracle的一些特殊机制
最开始的学习的时候,这些细节就让我很头疼
Oracle中,字段名,表名,用户名等 默认都是大写的。
比如:我用Navicat创建了个用户 sky03 ,登录的时候用 sky03,提示用户名/密码无效,其实Navicat在创建表或用户的时候,会自动加上双引号”sky03″(强制使用原大小写),真正的用户名为sky03。而Oracle会自动把不加双引号的 表或用户名 转大写,也就是说我登录的时候的用户名为SKY03,所以登录的时候加上双引号就行了”sky03″。所以为了以后使用方便,以后都用大写。
与MySQL不同的是,Oracle的事务是手动提交的,所以增删改查后都要手动提交事务(commit),不然都是脏数据!
Oracle数据库开启,并且存在会话的时候,不要直接关机,应该先把会话关掉,再关掉数据库(也可以不关数据库),再关机。不然的话,下次启动登录会报错:Oracle ORA-01033: ORACLE initialization or shutdown in progress 。
创建表空间
表空间:ORACLE 数据库的逻辑单元。 数据库—表空间 一个表空间可以与多个数据 文件(物理结构)关联
一个数据库下可以建立多个表空间,一个表空间可以建立多个用户、一个用户下可以建立 多个表。
创建表空间的语句:
create tablespace “sky03″datafile ‘c:\sky03.dbf’size 100mautoextend onnext 10m;
sky03:为表空间名称
datafile:指定表空间对应的数据文件
size:后定义的是表空间的初始大小
autoextend on:自动增长 ,当表空间存储都占满时,自动增长
next:后指定的是一次自动增长的大小。
最后会在安装Oracle数据库的电脑上创建c:\sky03.dbf此文件
删除表空间的语句为:
drop tablespace “sky03″创建用户创建用户
创建用户语句:
CREATE USER “SKY03” IDENTIFIED BY “admin” DEFAULT TABLESPACE “sky03”
CREATE USER:创建用户,后面是用户名
IDENTIFIED BY:后边是用户的密码
DEFAULT TABLESPACE:后边是表空间名称
Oracle 数据库与其它数据库产品的区别在于,表和其它的数据库对象都是存储在用户 下的。
这里有个东西要注意,就是如果创建的用户名里有小写字母,登录时就要在用户名上加双引号,Oracle会自动将不带双引号的用户名转大写,例如:
创建的用户名为sky03,登录时填写用户名就必须为”sky03″,不然就会提示用户名/口令无效,如果用户名为SKY03,登录时就可以直接填写SKY03或者sky03,密码是区分大小写的!
密码为特殊字符时,创建用户时密码需要加双引号,登陆时也需要把密码用双引号括起来。
给用户分配角色
新创建的用户没有角色身份,登陆后会提示
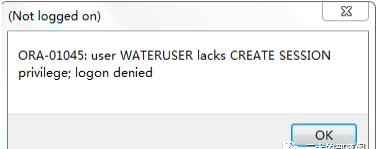
Oracle 中已存在三个重要的角色:connect 角色,resource 角色,dba 角色。
CONNECT 角色: –是授予最终用户的典型权利,最基本的
ALTER SESSION –修改会话
CREATE CLUSTER –建立聚簇
CREATE DATABASE LINK –建立数据库链接
CREATE SEQUENCE –建立序列
CREATE SESSION –建立会话
CREATE SYNONYM –建立同义词
CREATE VIEW –建立视图
RESOURCE 角色: –是授予开发人员的
CREATE CLUSTER –建立聚簇
CREATE PROCEDURE –建立过程
CREATE SEQUENCE –建立序列
CREATE TABLE –建表
CREATE TRIGGER –建立触发器
CREATE TYPE –建立类型
DBA 角色: 拥有全部特权,是系统最高权限,只有 DBA 才可以创建数据库结构,并且系统 权限也需要 DBA 授出,且 DBA 用户可以操作全体用户的任意基表,包括删除
授权语句:
GRANT “DBA” TO “SKY03”
之后就可以用该用户名登录了!
Oracle数据类型
No数据类型描述1Varchar, Varchar2表示一个字符串2NUMBERNUMBER(n)表示一个整数,长度是 nNUMBER(m,n):表示一个小数,总长度是 m,小 数是 n,整数是 m-n3DATA表示日期类型4CLOB大对象,表示大文本数据类型,可存 4G5BLOB大对象,表示二进制数据,可存 4G
Varchar2:常用,它会自动截取掉多余的字符长度
表的管理SQL的注释
SQL的单行注释为 —
多行注释为 /* … */
建表
语法:
Create table “用户名”.”表名”(
字段 1 数据类型 [default 默认值],
字段 2 数据类型 [default 默认值],
… 字段 n 数据类型 [default 默认值]
);
注意:”用户名”.”表名”,如果所使用的”用户名”已经是当前已经登录的用户,则可以省略不写,即:”表名”
范例:创建 person 表
CREATE TABLE “SKY03″.”person” ( “pid” NUMBER(10) NOT NULL , “name” VARCHAR2(10) , “gender” NUMBER(1) DEFAULT 1 , “birthday” DATE );INSERT INTO “SKY03”.”person”(“pid”, “name”, “gender”, “birthday”) VALUES (‘1’, ‘张三’, ‘1’, TO_DATE(‘2019-04-21 15:42:24’, ‘SYYYY-MM-DD HH24:MI:SS’));删表
三个删除
删除表中全部记录
DELETE FROM “person”;
删除表结构
DROP TABLE “person”;
先删除表,再次创建表。效果等同于 删除表中全部记录 。
在数据量大的情况下,尤其在表中带有索引的情况下,该操作效率高。
索引可以提高查询效率,但是会影响增删改效率
TRUNCATE TABLE “person”;表结构的增删改(字段)
在 sql 中使用 alter 可以修改表
添加字段:ALTER TABLE 表名称 ADD (字段 1 类型 [DEFAULT 默认值],字段 2 类型 [DEFAULT 默认值]…)
修改字段:ALTER TABLE 表名称 MODIFY (字段 1 类型 [DEFAULT 默认值],字段 2 类型 [DEFAULT 默认值]…)
修改字段名:ALTER TABLE 表名称 RENAME COLUMN 字段1 TO 字段 2
删除字段:ALTER TABLE 表名称 DROP COLUMN 字段
添加字段:
ALTER TABLE “SKY03″.”person” ADD (“address” varchar2(10) );
修改字段属性:
ALTER TABLE “SKY03″.”person” MODIFY (“birthday” VARCHAR2(7) );
修改字段名:
ALTER TABLE “SKY03″.”person” RENAME COLUMN “pid” TO “id” ;
删除字段:
ALTER TABLE “SKY03″.”person” DROP COLUMN “pid” ;表数据的增删改(记录)INSERT(增)
标准写法: INSERT INTO 表名[(列名 1,列名 2,…)]VALUES(值 1,值 2,…)
简单写法(不建议):INSERT INTO 表名 VALUES(值 1,值 2,…)
注意:使用简单的写法必须按照表中的字段的顺序来插入值,而且如果有为空的字段使用 null
另外,Oracle默认是手动提交事务的,所以此时插入的数据为脏数据,点下rollback,数据就没了,所以以后增删改都要提交事务。
MySQL中默认是自动提交事务,所以不用手动提交。
java中connection对象是默认自动提交事务的。
提交:commit
回滚:rollback
INSERT INTO “SKY03”.”person”(“pid”, “name”, “gender”, “birthday”) VALUES (‘1’, ‘张三’, ‘1’, TO_DATE(‘2019-04-21 15:42:24’, ‘SYYYY-MM-DD HH24:MI:SS’));COMMIT;DELETE(删)
语法 : DELETE FROM 表名 WHERE 删除条件;
在删除语句中如果不指定删除条件的话就会删除所有的数据
UPDATE(改)
全部修改:UPDATE 表名 SET 字段 1=值 1,字段 2=值 2,….
局部修改:UPDATE 表名 SET 字段 1=值 1,字段 2=值 2,….WHERE 修改条件;
序列 (SEQUENCE)
在MySQL中主键一般都是自增、唯一、非空的属性,在Oracle中也一样。MySQL用auto_increment完成以上需求,Oracle用的就是序列(SEQUENCE)。
序列是不属于任何一张表,但是可以和表做绑定。
创建序列
语法:
CREATE SEQUENCE 序列名 [相关参数]
— s代表序列,person代表是person表的序列CREATE SEQUENCE s_person;
参数:(一般不用,了解)
INCREMENT BY :序列变化的步进,负值表示递减。(默认1)
START WITH:序列的初始值 。(默认1)
MAXVALUE:序列可生成的最大值。(默认不限制最大值,NOMAXVALUE)
MINVALUE:序列可生成的最小值。(默认不限制最小值,NOMINVALUE)
CYCLE:用于定义当序列产生的值达到限制值后是否循环(NOCYCLE:不循环,CYCLE:循环)。
CACHE:表示缓存序列的个数,数据库异常终止可能会导致序列中断不连续的情况,默认值为20,如果不使用缓存可设置NOCACHE
修改或删除序列
使用 alter 命令进行修改
使用 drop 命令删除
序列的使用
currval 表示序列的当前值,刚建好的序列没有当前值,必须先执行一次nextval 才能获取到值,否则会报错!
nextval 表示序列的下一个值。新序列首次使用时获取的是该序列的初始值,从第二次使用时开始按照设置的步进递增。
查询序列的值:select s_person.[currval/nextval] from dual;
其中dual为虚表,只是为了补全语法,没有任何意义,因为Oracle中查询语句必须带有from关键词,所以采用虚表。
SQL语句中使用:insert into table (id) values (s_person.nextval)
Scott用户
简单来说,Scott用户是Oracle专门给新手练习用的账户,自带的有一些表。但是12c版本的数据库没有Scott账户,但是有Scott账户的SQL文件,可以恢复。具体教程 点这里。
函数
数据库的增删改查,难的就是查,尤其是多表查询,当涉及到复杂查询,就必须使用函数。
Oracle中的函数分为 单行函数 和 多行函数
单行函数
作用于一行,返回一个值
字符函数
upper(‘yes’) 字符小写转大写
select upper(‘yes’) from dual; — 结果是 YES
lower(‘YES’) 字符大写转小写
select upper(‘YES’) from dual; — 结果是 yes
数值函数
round() 四舍五入
— 第二个参数:正数,保留小数点后几位;负数,保留小数点前几位;0或不写,不保留小数。select round(26.16,1) from dual; — 26.2select round(26.16,-1) from dual; — 30select round(26.16,-2) from dual; — 0select round(56.16,-2) from dual; — 100
trunc() 截取数字
— 第二个参数:正数,保留小数点后几位,其他舍去;负数,保留小数点前几位,其他舍去;0或不写,舍去小数。select trunc(26.16,1) from dual; — 26.1select trunc(26.16,-1) from dual; — 20select trunc(26.16,-2) from dual; — 0
mod() 求余
— 第一个参数对第二个参数求余select mod(26.16,1) from dual; — 0.16select mod(10,3) from dual; — 1
日期函数
sysdate 表示当前系统时间
–查询出emp表中所有员工入职距离现在几天。 最后的e是emp的别名select sysdate-e.hiredate from emp e;–算出明天此刻select sysdate 1 from dual;–查询出emp表中所有员工入职距离现在几月。select months_between(sysdate,e.hiredate) from emp e;–查询出emp表中所有员工入职距离现在几年。select months_between(sysdate,e.hiredate)/12 from emp e;–查询出emp表中所有员工入职距离现在几周。select round((sysdate-e.hiredate)/7) from emp e;
转换函数
to_char() 日期转字符串
select to_char(sysdate, ‘yyyy-mm-dd hh:mi:ss’) from dual;– 2019-04-22 11:49:43select to_char(sysdate, ‘fm yyyy-mm-dd hh:mi:ss’) from dual;– 2019-4-22 11:49:14 (月日不带0)select to_char(sysdate, ‘fm yyyy-mm-dd hh24:mi:ss’) from dual;– 2019-4-22 23:50:10 (24小时制)
to_date() 字符串转日期
select to_date(‘2018-6-7 16:39:50’, ‘fm yyyy-mm-dd hh24:mi:ss’) from dual;– 2018/6/7 16:39:50 注意结果是日期类型的
通用函数
nvl(参数1,参数2) 如果参1为null值,就返回参2,如果参1不为null,则返回参1
–算出emp表中所有员工的年薪。–奖金里面有null值,如果null值和任意数字做算术运算,结果都是null。select e.sal*12 nvl(e.comm, 0) from emp e;通用函数
通用函数,在MySQL和Oracle里通用!
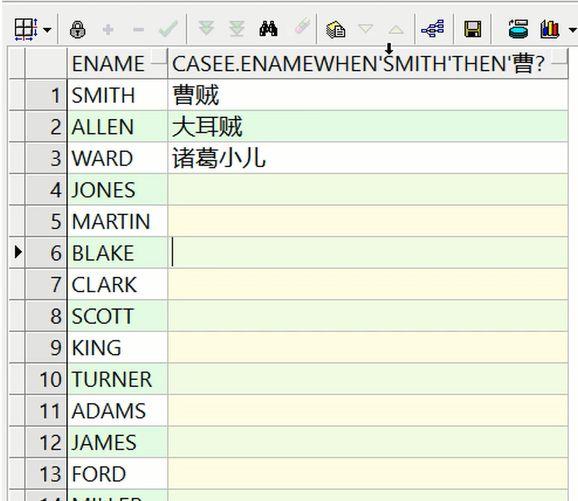
when then 条件表达式
—给emp表中员工起中文名—等值判断select e.ename, case e.ename when ‘SMITH’ then ‘曹贼’ when ‘ALLEN’ then ‘大耳贼’ when ‘WARD’ then ‘诸葛小儿’ else ‘无名’ endfrom emp e;– 结果:emp表的员工名前三个会自动改掉,其他的走else
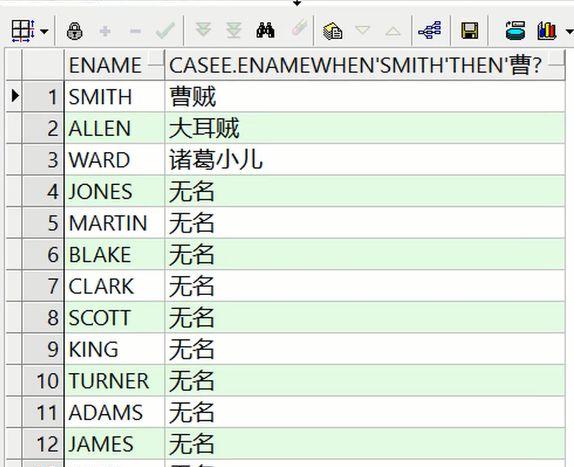
—给emp表中员工起中文名—等值判断select e.ename, case e.ename when ‘SMITH’ then ‘曹贼’ when ‘ALLEN’ then ‘大耳贼’ when ‘WARD’ then ‘诸葛小儿’ –else ‘无名’ endfrom emp e;– 结果:没有指定名字的,全部变成null值– 一般可以用于批量将记录的某字段变为null值– 其实这里的when后相当于 e.ename=’SMITH’
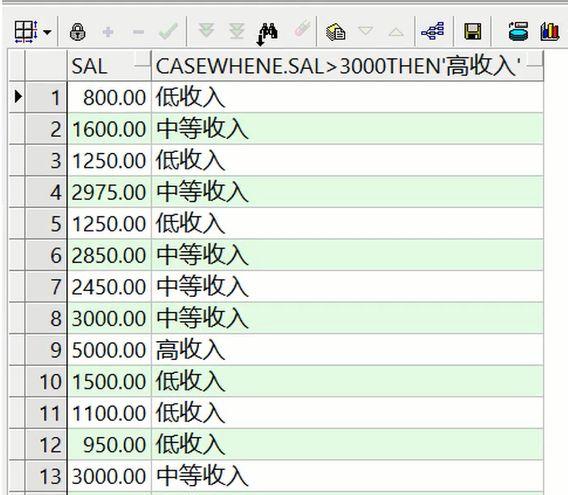
—判断emp表中员工工资,如果高于3000显示高收入,如果高于1500低于3000显示中等收入,—–其余显示低收入—–范围判断select e.sal, case when e.sal>3000 then ‘高收入’ when e.sal>1500 then ‘中等收入’ else ‘低收入’ endfrom emp e;
用法三:
用法二:
用法一:
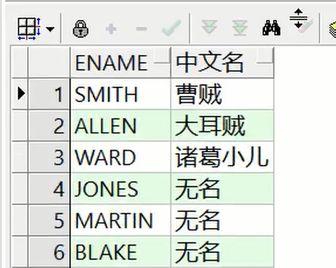
decode() Oracle专用表达式,作用和 when then 一样
—-oracle专用条件表达式—-oracle中除了起别名,都用单引号。select e.ename, decode(e.ename, ‘SMITH’, ‘曹贼’, ‘ALLEN’, ‘大耳贼’, ‘WARD’, ‘诸葛小儿’, ‘无名’) “中文名” –双引号可以去掉,但是不能用单引号from emp e;
我们开发人员讲究代码可重用,最好使用通用函数,MySQL和Oracle都能用!
多行函数(聚合函数)
作用于多行,返回一个值
count() 统计记录数
select count(1) from emp;—查询总数量– 有时候写的是count(*),其实底层走的还是count(1)– count(1)的意思是count(第一个字段)
sum() 求和函数
select sum(sal) from emp;—工资总和
max() 最大值
select max(sal) from emp;—最大工资
min() 最小值
select min(sal) from emp;—最低工资
avg() 平均值
select avg(sal) from emp;—平均工资查询分组查询
关键字 group by
语法:SELECT 分组字段 [聚合函数] FROM 表名 {GROUP BY 分组字段}
select e.sex, avg(e.age) –, e.enamefrom emp egroup by e.sex;– 整个语句意思是 以性别为组,统计男女的平均年龄
分组查询中,出现在group by后面的原始列,才能出现在select后面
没有出现在group by后面的列,想在select后面,必须加上聚合函数。
不能使用别名当条件
因为一般条件的执行顺序高于查询
例如: where的执行优先级高于select,所以s是无效的
select ename, sal s from emp where s>1500; –不能执行
正确:
select ename, sal s from emp where sal>1500;
where和having的区别
select e.deptno, avg(e.sal)from emp egroup by e.deptnohaving avg(e.sal)>2000;select e.deptno, avg(e.sal) asalfrom emp ewhere e.sal>800group by e.deptno;
where是过滤分组前的数据,having是过滤分组后的数据。
表现形式:where必须在group by之前,having是在group by之后。
先查询出每个部门工资高于800的员工的平均工资,然后再查询出平均工资高于2000的部门:
select e.deptno, avg(e.sal) asalfrom emp ewhere e.sal>800group by e.deptnohaving avg(e.sal)>2000;
查询出每个部门工资高于800的员工的平均工资
查询出平均工资高于2000的部门信息
多表查询多表查询中的一些概念
笛卡尔积
select * from emp e, dept d;
emp有14条记录,dept有4条记录,查询出来的结果为14*4=56条记录,其中大部分没有意义
等值连接
select * from emp e, dept dwhere e.deptno=d.deptno;– 查询出主键相等的信息 14条信息
内连接(老版的等值连接)
select *from emp e inner join dept don e.deptno = d.deptno;
外连接(左连接和右连接)
–查询出所有部门,以及部门下的员工信息select *from emp e right join dept don e.deptno=d.deptno;—查询所有员工信息,以及员工所属部门select *from emp e left join dept don e.deptno=d.deptno;
oracle中专用外连接
select *from emp e, dept dwhere e.deptno( ) = d.deptno;
自连接:其实就是站在不同的角度把一张表看成多张表。
— 查询出员工姓名,员工领导姓名,员工和领导都在emp表select e1.ename, e2.enamefrom emp e1, emp e2where e1.mgr = e2.empno;子查询
在一个查询的内部还包括另一个查询,则此查询称为子查询。
Sql的任何位置都可以加入子查询。
单列子查询,返回一列的一个内容
—查询出工资和SCOTT一样的员工信息select * from emp where sal in –如果确定是ename是惟一的,in可以换成=(select sal from emp where ename = ‘SCOTT’);
单行子查询,返回多个列,有可能是一个完整的记录
—查询出工资和10号部门任意员工一样的员工信息select * from emp where sal in(select sal from emp where deptno = 10);
多行子查询,返回多条记录
—查询出每个部门最低工资,和最低工资员工姓名,和该员工所在部门名称—1,先查询出每个部门最低工资select deptno, min(sal) msalfrom emp group by deptno;—2,三表联查,得到最终结果。select t.deptno, t.msal, e.ename, d.dnamefrom (select deptno, min(sal) msal from emp group by deptno) t, emp e, dept dwhere t.deptno = e.deptnoand t.msal = e.saland e.deptno = d.deptno;分页查询—rownum行号:当我们做select操作的时候,–每查询出一行记录,就会在该行上加上一个行号,–行号从1开始,依次递增,不能跳着走。—-排序操作会影响rownum的顺序select rownum, e.* from emp e order by e.sal desc—-如果涉及到排序,但是还要使用rownum的话,我们可以再次嵌套查询。select rownum, t.* from(select rownum, e.* from emp e order by e.sal desc) t;—-emp表工资倒叙排列后,每页五条记录,查询第二页。—-rownum行号不能写上大于一个正数。select * from( select rownum rn, tt.* from( select * from emp order by sal desc ) tt where rownum<11) where rn>5视图
视图的概念:视图就是封装了一条复杂查询的语句,提供一个查询的窗口,所有数据来自于原表。
创建视图
创建视图必须有DBA权限
语法1:CREATE VIEW 视图名称 AS 子查询
create view v_emp as select ename, job from emp;
语法2:CREATE OR REPLACE VIEW 视图名称 AS 子查询
如果视图已经存在我们可以使用语法2来创建视图,这样已有的视图会被覆盖。
查询视图
跟普通查询没什么区别:
select * from v_emp;修改视图
跟普通update没什么区别,视图修改的是原表的数据,不推介修改视图
update v_emp set job=’CLERK’ where ename=’ALLEN’;commit;创建只读视图
为了防止修改视图还可以创建只读视图
create view v_emp1 as select ename, job from emp with read only;视图的作用
视图可以屏蔽掉一些敏感字段。
保证总部和分部数据及时统一。
索引概念
索引就是在表的列上构建一个二叉树。
达到大幅度提高查询效率的目的,但是索引 会影响增删改的效率。
索引分为 单列索引 和 复合索引
单列索引
查询条件必须是索引列中的原始值。
单行函数,模糊查询,都会影响索引的触发。
创建单列索引
语法:CREATE index 索引名 on 表名(列名)
create index idx_ename on emp(ename);
单列索引触发规则
复合索引
假设以上单列索引和复合索引同时存在
复合索引中第一列为优先检索列。
触发复合索引,必须包含有优先检索列中的原始值。
创建复合索引
create index idx_enamejob on emp(ename, job);
复合索引触发规则
示例:
select * from emp where ename=’SCOTT’ and job=’xx’;—触发复合索引select * from emp where ename=’SCOTT’;—触发单列索引。select * from emp where ename=’SCOTT’ or job=’xx’;—这个相当于两条查询语句,一个条件为or的前者,触发单列索引;一个条件为or的后者,不触发任何索引。—or到一起,就是不触发索引PL/SQL编程语言
pl/sql编程语言是对sql语言的扩展,使得sql语言具有过程化编程的特性。
pl/sql编程语言比一般的过程化编程语言,更加灵活高效。
pl/sql编程语言主要用来编写存储过程和存储函数等。
基本语法declare 说明部分 (变量说明,游标申明,例外说明 〕 begin 语句序列 (DML语句〕… exception 例外处理语句 End;
示例:
赋值操作可以使用:=也可以使用into查询语句赋值
declare i number(2) := 10; — `:=`是赋值的意思,相当于Java里的 `=` s varchar2(10) := ‘小明’; ena emp.ename%type;—引用型变量 emprow emp%rowtype;—记录型变量begin dbms_output.put_line(i); –输出变量 dbms_output.put_line(s); select ename into ena from emp where empno = 7788; dbms_output.put_line(ena); select * into emprow from emp where empno = 7788; dbms_output.put_line(emprow.ename || ‘的工作为:’ || emprow.job); — 双竖线`||`是连接字符串的符号end;if判断语句
需求:
输入小于18的数字,输出未成年
输入大于18小于40的数字,输出中年人
输入大于40的数字,输出老年人
语法:
declare i number(3) := &i; — &i表示键盘输入,&后可以跟任何变量begin if i<18 then dbms_output.put_line(‘未成年’); elsif i<40 then — elsif相当于else if dbms_output.put_line(‘中年人’); else dbms_output.put_line(‘老年人’); end if; –if语句结束再加分号;end;loop循环
需求: 用三种方式输出1到10是个数字
while循环
declare i number(2) := 1;begin while i<11 loop i小于11,就一直循环 dbms_output.put_line(i); i := i 1; end loop;end;
exit循环
declare i number(2) := 1;begin loop exit when i>10; — 当i大于10的时候推出循环 dbms_output.put_line(i); i := i 1; end loop;end;
for循环
declarebegin for i in 1..10 loop — 变量i 从1循环到10结束 dbms_output.put_line(i); end loop;end;游标
游标可以存放多个对象,多行记录。
需求:输出emp表中所有员工的姓名
declare cursor c1 is select * from emp; emprow emp%rowtype;begin open c1; loop fetch c1 into emprow; exit when c1%notfound; dbms_output.put_line(emprow.ename); end loop; close c1;end;