一. 客户细分的方法
1. 细分方法
细分过程的概念框架是基于“推断”细分过程的。
这里以“增强细分”的细分方法为例。“增强细分”是将客户分组,以明确推断客户期望(对考虑的价值)。这种推断通常是通过使用描述性特征来完成的,这些特征代表或被推定为像兴趣、期望或要求这样推断的替代的角色。
“增强细分”通常用于推断给定细分的基本需求,因为它假设所有成员都有一组共同的需求,比如,IBM负责销售的流动员工, 对这一群体的具体期望和要求可以有把握地推断出来。同样重要的是,可以识别特定的标识,这些标识提供了识别组成员身份的能力。
2. 本文以下引用的假设研究对象是IBM公司
IBM拥有30万员工
是一个庞大的跨国企业
复杂的跨种族与跨民族的群体
几千种不同的工作岗位
…
IBM公司在对员工行为和需求引用细分的方法,通过细分和归类,找出给与特定的员工以特定的工作环境和条件,使之可以有一个快速进入工作状态的条件,以及未来持续工作所需要的个性化的培训计划,再进一步利用设计好的晋升途径模板为其规划未来的发展方向。。。。。。试想一下,如果这些员工都是客户的话,应该如何管理?又应该如何使他们都能得到照顾?又如何使他们都具有较高的满意度?
3.细分八步法
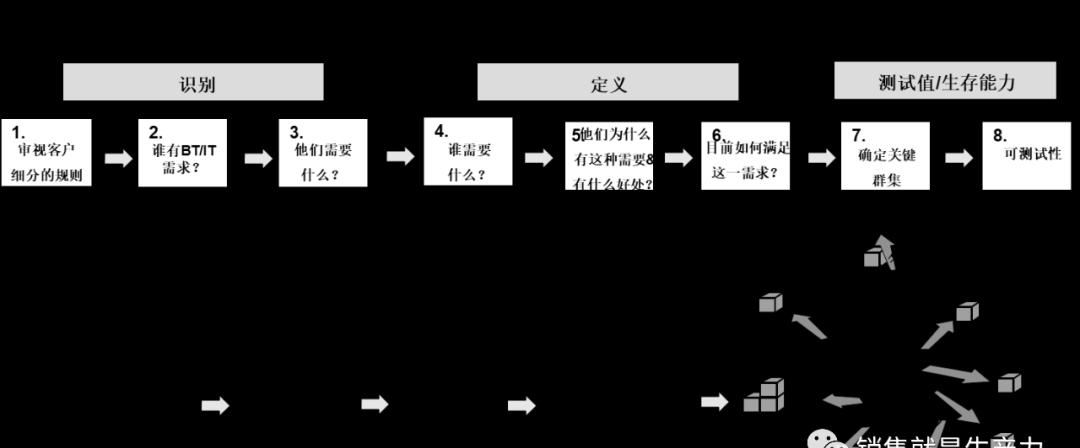
细分八步法在识别阶段的目的是细化细分需求,建立完成增强细分方案所必需的数据需求。

谁–要细分的客户:他们是谁? 用什么特征来区分这一个部分和另一个部分?
客户所在地– 他们位于不同的地理位置?他们是否围绕某些性能特征自然地组织起来?
什么– 是否存在一组“指标”变量/参数,从这些变量/参数中可以推断出客户的性能需求和要求?
为什么– 从完成细分方案中获得的策略利益是什么?
细分效益的评估依据是:
(1)可识别性
(2)实质性
(3)可及性
(4)稳定性
(5)响应性
(6)可操作性
细分八步法的有效性是根据以上六个标准来衡量的,这些标准定义了所产生的组织方案的质量和有用性。
可识别性是根据用于定义组成员资格的变量/参数,细分的用户能够识别目标人群中真实组的程度。
如果识别出的目标代表了足够大的目标群体的部分,那么这个细分努力是值得的,则满足实质性标准。
可及性是细分成员能够被触及、指导和支持的程度。
稳定性是细分可靠度的保证。是否因为使用了这些基础变量/参数,从而在需求和策略反应方面实现了合理的永久性分类?
响应性是衡量细分成员对为满足细分推断的需求而提供的消息传递和性能支持特性的接受程度(愿意为之提供和接受正确的信息)。
如果细分识别为决策和战略影响提供指导(可操作性),则可采取行动。
细分八步法中的组件和模块职责
在完成细分过程的细分步骤时,有五个必要的模块:
确立细分目标:细分的目标应该十分明确,简洁直接,结果可见。这就是细分过程的总纲指导。
确定目标人群特征:提供目标人群的对象、地点和内容。哪些变量或特征将被用来定义和区分细分?
建立聚类流程:增强细分依赖于使用迭代聚类分析和/或设计的类似于市场篮子(这是对消费者采购行为分析的主要方法)分析的关联规则来确定派生细分的大小、组成和数量。
设计细分标签特征:需要根据选定的人口统计或原始数据变量对每个部分进行分析,这些分析文件保证了细分方案的可识别性和可操作性。
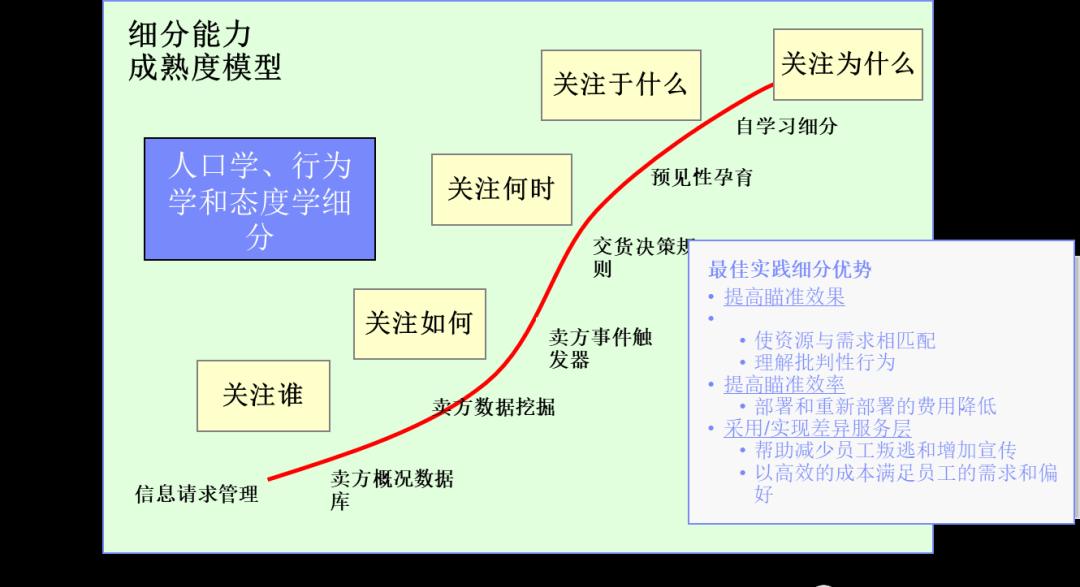
二. 细分能力成熟度的最佳实践方法是细分过程的最终目标
通过评估以上六个标准设计的细分性能能力,我们可以沿着一个细分成熟的连续曲线持续前进,逐步向稳定的、自我校正的细分算法迈进。下图展现了客户细分能力成熟度的成熟轨迹,这个轨迹清晰地告诉我们,细分工作是如何逐步演进并向高级阶段发展的。
三. 细分采用的工具与方法
客户细分的工作需要基于大量的数据和输入,同时也需要用一些科学的工具进行有效地分析,通过分析得出这些数据的相互关系以及预示的逻辑。下图是在做客户细分时常用的分析工具与方法:
聚类/集群分析是一个非常有用的工具,当试图将客户分组成具有相同需求/兴趣的合理的同质部分时,聚类分析通常能比较直观地表达。
开发增强细分的IBM员工群体的主要分析引擎是非重叠、非分层的聚类方法,这种方法不在数据中寻找树结构。相反, 它们将数据划分为预定数量的段。下列是聚类分析的大致做法,供大家参考,具体如何使用和实现,可以参照有关的资料处理。
最小化或最大化某种利益标准。这类细分的方法根据被优化的准则和为优化过程选择的算法而不同。这些K-均值优化“通过”(也称为最近质心排序通过)将个体重新分配到可能的最近质心。K均值分析的计算程序包括:
计算分配给每个初始集群的所有案例的“重心”。所述计算确定空间中的位置,使得特定簇中的所有情况到所选中心位置的平方欧几里德距离在所有维度上都是最小的。这个位置被称为集群质心,通常位于构成集群的应答者最大密度附近;
质心反过来被用作新簇的种子,因为它们比最初随机选择的种子更有意义;
计算所有with-cluster应答者到每个新质心的距离,以开始下一次迭代;
将每个情况分配给它最接近的质心,并再次进行迭代;
继续迭代,直到质心的进一步移动不会在任何一个簇内产生统计上显著的同质性改进。
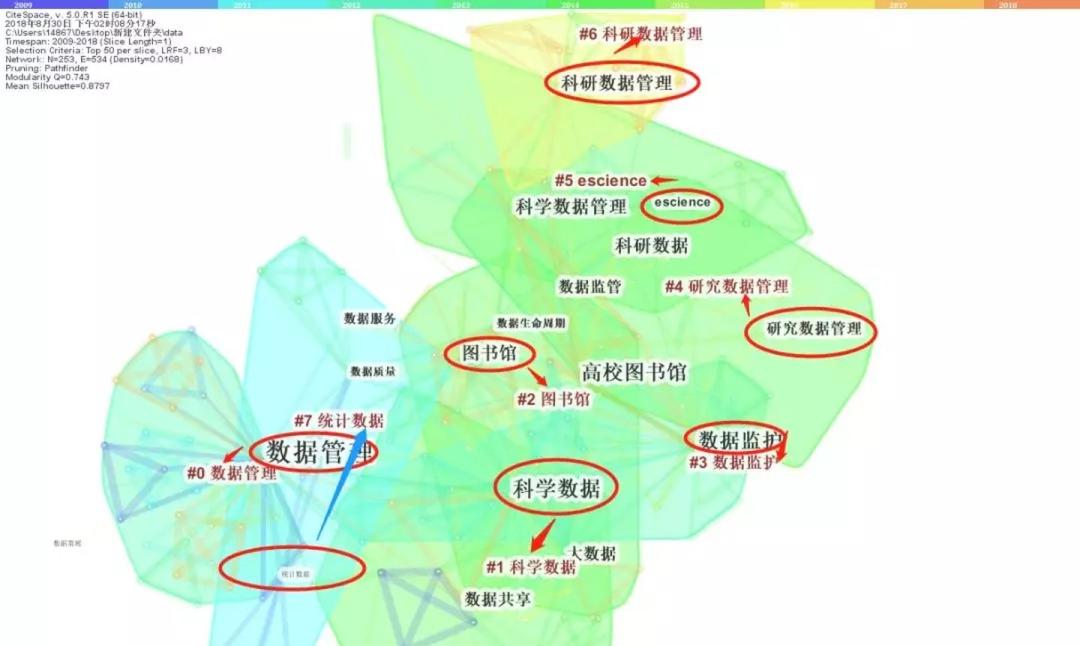
下图是一个关键词聚类分析图表举例,用以表达通过聚类分析所得到的分析结果。顺序是从0到7,数字越小,聚类中包含的关键词越多,每个聚类是多个紧密相关的词组成的,具体是那些关键词可以通过选择得到详细信息。
关联规则是从大量事务数据中开发密切相关关系组的极好工具。它经常与聚类技术一起用于构造预测算法。
关联规则用于在大型事务性数据库中建立关系已经有一段时间了。当使用关联规则作为细分驱动时,有三个重要的问题需要注意。
1.项目或数据点的选择非常重要。通常可以使用聚类分析的分析结果来确定要在分析中使用的最显著的事务数据点集;
2.必须制定一个共现矩阵,使关联和非关联的宏观规则变得明显;
3.维护一个允许开发的规则在最重要的数据点上运行的最小数据集,而不是使用一个允许“影子”关联的数据库,这种关联可能是有趣的,但对于手头的细分任务来说并不重要。
关联规则的发展有三个广泛的步骤,其中包括:
1.在正确的层次上确定正确的项目进行分析。例如,知道一台笔记本电脑是做特定工作所必需的就足够了,还是应该是某种类型的笔记本电脑?
2.计算感兴趣的项目和组合的概率和联合概率。可以通过引入重要性的接受阈值来限制搜索。
3.分析建立正确的关联规则的概率。如果IBM某特定工作是X,那么需要便携机Y型号。
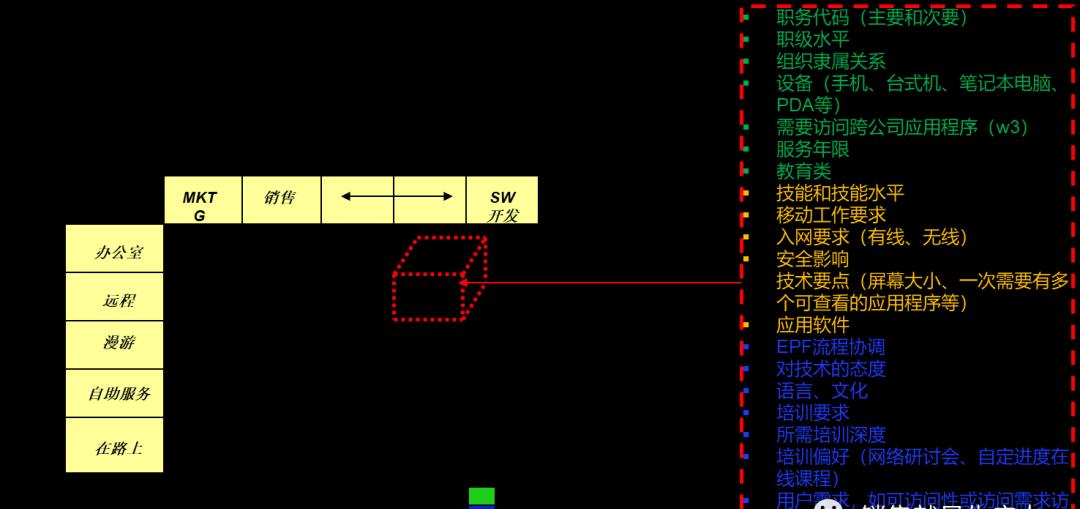
四. 细分过程的结果
下图展现了以IBM员工为研究对象的关联规则分析,右图是关联矩阵,左图是分类标签,图中红色虚线部分则表示出经过关联分析后的针对某一员工的需求预判。