在《学习必备!详解Hadoop的分布式文件系统》(http://t.cn/R54XZyi)文章中,我们从Hadoop HDFS的背景、基本概念、设计目标以及HDFS的基本结构等方面,已经对HDFS进行了比较全面的了解。
开始咯!

Hadoop之HDFS文件操作常有两种方式,一种是命令行方式,即Hadoop提供了一套与Linux文件命令类似的命令行工具;另一种是JavaAPI,即利用Hadoop的Java库,采用编程的方式操作HDFS的文件。
调用文件系统(FS)Shell命令的基本形式为:
bin/hadoop fs <args>
所有的的FS shell命令使用URI路径作为参数。URI格式是scheme://authority/path。对HDFS文件系统,scheme是hdfs,对本地文件系统,scheme是file。其中scheme和authority参数都是可选的,如果未加指定,就会使用配置中指定的默认scheme。
一个HDFS文件或目录。比如:/parent/child,可以表示成:hdfs://namenode:namenodeport/parent/child,或者更简单的/parent/child(假设你配置文件中的默认值是namenode:namenodeport)。大多数FS Shell命令的行为和对应的Unix Shell命令类似,不同之处会在介绍各命令使用详情时指出。出错信息会输出到stderr,其他信息输出到stdout。
1.appendToFile
使用方法:
hadoop fs -appendToFile <localsrc> … <dst>
从本地文件系统中的单个、或多个src,复制到目标文件系统。
示例:
hadoop fs -appendToFile localfile /user/hadoop/hadoopfile
hadoop fs -appendToFile localfile1 localfile2 /user/hadoop/hadoopfile
hadoop fs -appendToFile localfile hdfs://nn.example.com/hadoop/hadoopfile
hadoop fs -appendToFile – hdfs://nn.example.com/hadoop/hadoopfile Reads the input fromstdin.
返回值:
成功返回0,失败返回1。
2.cat
使用方法:
hadoop fs -cat URI [URI …]
将路径指定文件的内容输出到stdout。
示例:
hadoop fs -cat hdfs://host1:port1/file1 hdfs://host2:port2/file2
hadoop fs -cat file:///file3 /user/hadoop/file4
返回值:
成功返回0,失败返回-1。
3.checksum
使用方法:
hadoop fs -checksum URI
返回一个文件的checksum信息。
示例:
hadoop fs -checksum hdfs://nn1.example.com/file1
hadoop fs -checksum file:///etc/hosts
4.chgrp
使用方法:
hadoop fs -chgrp [-R] GROUP URI [URI …]
改变文件所属的组。使用-R将使改变在目录结构下递归进行。命令的使用者必须是文件的所有者或者超级用户。更多的信息请参见:
HDFS权限用户指南:http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/HdfsPermissionsGuide.html
5.chmod
使用方法:
hadoop fs -chmod [-R] <MODE[,MODE]… | OCTALMODE> URI [URI …]
改变文件的权限。使用-R将使改变在目录结构下递归进行。命令的使用者必须是文件的所有者或者超级用户。更多的信息请参见:
HDFS权限用户指南:http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/HdfsPermissionsGuide.html
6.chown
使用方法:
hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
改变文件的拥有者。使用-R将使改变在目录结构下递归进行。命令的使用者必须是超级用户。更多的信息请参见:
HDFS权限用户指南:http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/HdfsPermissionsGuide.html
7.copyFromLocal
使用方法:
hadoop fs -copyFromLocal <localsrc> URI
除了限定源路径是一个本地文件外,和put命令相似。
8.copyToLocal
使用方法:
hadoop fs -copyToLocal [-ignorecrc] [-crc] URI <localdst>
除了限定目标路径是一个本地文件外,和get命令类似。
9.count
使用方法:
hadoop fs -count [-q] [-h] [-v] <paths>
目录、文件、字节匹配指定的文件模式的路径下的数量。
与-count输出的栏目有:DIR_COUNT,FILE_COUNT,CONTENT_SIZE,PATHNAME
与-count -q输出的栏目有: QUOTA,REMAINING_QUATA,SPACE_QUOTA,REMAINING_SPACE_QUOTA,DIR_COUNT,FILE_COUNT,CONTENT_SIZE,PATHNAME
-h选项显示可读的格式大小。
-v 选项显示的标题行。
示例:
hadoop fs -count hdfs://nn1.example.com/file1 hdfs://nn2.example.com/file2
hadoop fs -count -q hdfs://nn1.example.com/file1
hadoop fs -count -q -h hdfs://nn1.example.com/file1
hdfs dfs -count -q -h -v hdfs://nn1.example.com/file1
返回值:
成功返回0,失败返回-1。
10.cp
使用方法:
hadoop fs -cp [-f] [-p | -p[topax]] URI [URI …] <dest>
将文件从源路径复制到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。
示例:
hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2
hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2 /user/hadoop/dir
返回值:
成功返回0,失败返回-1。
11.createSnapshot
参见HDFS快照指南:http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/HdfsSnapshots.html
12.deleteSnapshot
参见HDFS快照指南:http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/HdfsSnapshots.html
13.df
使用方法:
hadoop fs -df [-h] URI [URI …]
显示可用空间。
示例:
hadoop dfs -df /user/hadoop/dir1
14.du
使用方法:
hadoop fs -du [-s] [-h] URI [URI …]
显示目录中所有文件的大小,或者当只指定一个文件时,显示此文件的大小。
示例:
hadoop fs -du /user/hadoop/dir1 /user/hadoop/file1 hdfs://nn.example.com/user/hadoop/dir1
返回值:
成功返回0,失败返回-1。
15.dus
使用方法:
hadoop fs -dus <args>
显示文件长度的摘要。
注意:此命令已被弃用,你可以利用 hadoop fs -du -s来替代它。
16.expunge
使用方法:
hadoop fs -expunge
清空回收站。请参考HDFS架构指南(http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html)以获取更多关于回收站功能的详细信息。
17.find
使用方法:
hadoop fs -find <path> … <expression> …
查找匹配指定表达式的所有文件,并将它们应用于选定的操作。如果没有指定路径,则默认为当前工作目录。如果没有指定的表达式,则默认为-print。
示例:
hadoop fs -find / -name test -print
返回值:
成功返回0,失败返回-1。
18.get
使用方法:
hadoop fs -get [-ignorecrc] [-crc] <src> <localdst>
复制文件到本地文件系统。可用-ignorecrc选项复制CRC校验失败的文件。使用-crc选项复制文件以及CRC信息。
示例:
hadoop fs -get /user/hadoop/file localfile
hadoop fs -get hdfs://nn.example.com/user/hadoop/file localfile
返回值:
成功返回0,失败返回-1。
19.getfacl
使用方法:
hadoop fs -getfacl [-R] <path>
显示文件和目录的访问控制列表(ACL)。如果一个目录有一个默认的ACL,getfacl依然会显示默认ACL.d
选项:
-R:列出所有文件及子目录的访问控制列表。
path:列出文件或目录。
示例:
hadoop fs -getfacl /file
hadoop fs -getfacl -R /dir
返回值:
成功返回0,失败返回非零。
20.getfattr
使用方法:
hadoop fs -getfattr [-R] -n name | -d [-e en] <path>
显示一个文件或目录的扩展属性名和值。
选项:
-R:递归列表中的所有文件和目录的属性。
-n name:转储命名的扩展属性值。
-d:转储与路径相关联的所有扩展属性值。
-e encoding:回收后的有效编码值为“text”, “hex”, and “base64”
path:文件和目录。
示例:
hadoop fs -getfattr -d /file
hadoop fs -getfattr -R -n user.myAttr /dir
返回值:
成功返回0,失败返回非零。
译自
Apache Hadoop 2.7.2官方文档
注明:本文为原创文章
不知道,大家是否有所收获呢?
 后续,数据妞会为大家分享《Hadoop HDFS常用文件操作命令(二)》的内容。
后续,数据妞会为大家分享《Hadoop HDFS常用文件操作命令(二)》的内容。
大家在文章中也可以看出,Hadoop的学习也是有一定的门槛的。大家需要掌握Java、Linux以及Shell编程方面的基础知识,才可以有条不紊地开始Hadoop的学习之旅哦!
另外,如果大家希望数据妞分享一些Java、Linux相关的学习资源,也欢迎给我留言哦!数据妞的备货,其实还是蛮多哒!
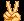

大数据学习家园