
总第440篇
2021年 第010篇

设计稿(UI视图)转代码是前端工程师日常不断重复的工作,这部分工作复杂度较低但工作占比较高,所以提升设计稿转代码的效率一直是前端工程师追求的方向之一。此前,前端工程师尝试过将业务组件模块化构建成通用视图库,并通过拖拽、拼接等形式搭建业务模块,从而实现视图复用,降低设计稿转代码的研发成本。但随着业务的发展和个性化的驱动,通用视图库无法覆盖所有应用场景,本文提出了一种设计稿自动生成代码的方案。1 背景
设计稿(UI视图)转代码是前端工程师日常不断重复的工作,这部分工作复杂度较低但工作占比较高,所以提升设计稿转代码的效率一直是前端工程师追求的方向之一。此前,前端工程师尝试过将业务组件模块化构建成通用视图库,并通过拖拽、拼接等形式搭建业务模块,从而实现视图复用,降低设计稿转代码的研发成本。但随着业务的发展和个性化的驱动,通用视图库无法覆盖所有应用场景,本文提出了一种设计稿自动生成代码的方案。
目前,业内主流的代码生成方案有两种,一种是通过训练神经网络,从图片或草图直接生成代码,以微软sketch2json为代表;另一种是基于Sketch源文件,从中解析出图层信息转化成DSL并生成代码,以imgCook为代表。
经过实践,我们发现第一种方案基于神经网络的代码生成算法虽然简单粗暴,但复杂层布局的准确率较低、可解释程度不高导致后续无法持续优化。方案二中Sketch源文件信息量丰富、算法自定义程度高、优化空间大。因此,我们调研了业界基于Sketch的代码自动生成方案(已对外公布或者开源),发现了一些不足并尝试解决,下面从算法准确率、代码可读性、研发流程覆盖度等方面做一下对比(该对比结果仅考察业界方案对我们自己业务的适用性,实际结果可能存在差异):
 算法准确率方面:淘宝imgCook支持基于AI的组件识别,不支持成组布局,准确率中等(从官网了解到可以识别循环布局,但不能识别出测试样本中的循环布局),58 Picasso仅支持原始组件的识别,复杂组件生成错误较多,不支持成组/悬浮/循环布局,准确率较低。代码可读性方面:淘宝imgCook在生成布局时,测试样本中图层重叠区域使用到了基于根布局的绝对定位方式,不符合RD预期,可读性一般,而我们的方案使用相对定位方式,可读性较好。研发流程覆盖度方面:淘宝imgCook从RD视角构建了一个IDE,支持在IDE中完成样式调整、逻辑绑定;而我们的方案从产研协作视角出发,支持数据、逻辑、埋点的可视化配置及上线。2 方案介绍
算法准确率方面:淘宝imgCook支持基于AI的组件识别,不支持成组布局,准确率中等(从官网了解到可以识别循环布局,但不能识别出测试样本中的循环布局),58 Picasso仅支持原始组件的识别,复杂组件生成错误较多,不支持成组/悬浮/循环布局,准确率较低。代码可读性方面:淘宝imgCook在生成布局时,测试样本中图层重叠区域使用到了基于根布局的绝对定位方式,不符合RD预期,可读性一般,而我们的方案使用相对定位方式,可读性较好。研发流程覆盖度方面:淘宝imgCook从RD视角构建了一个IDE,支持在IDE中完成样式调整、逻辑绑定;而我们的方案从产研协作视角出发,支持数据、逻辑、埋点的可视化配置及上线。2 方案介绍
如图所示,配置平台主要分成三块包括:设计稿转视图树(UI2DSL)、视图树转代码(DSL2Code)、以及业务信息绑定,下面简单介绍一下每一块的作用。
UI2DSL主要经历以下四个步骤:
 2.1.1 设计稿导入
2.1.1 设计稿导入
在日常开发过程中,我们接触比较多的组件有按钮、标题、进度条、评分组件等,但是Sketch数据源中并没有这些组件只有图层信息,图层是设计师在设计UI视图时用到的视图控件。组件与图层的对应关系是一对多的关系,图层在Sketch数据源中的表现形式如下图中的JSON数据结构所示,描述了图层的坐标、大小等信息,后续布局生成就是基于对图层的切割来实现的。
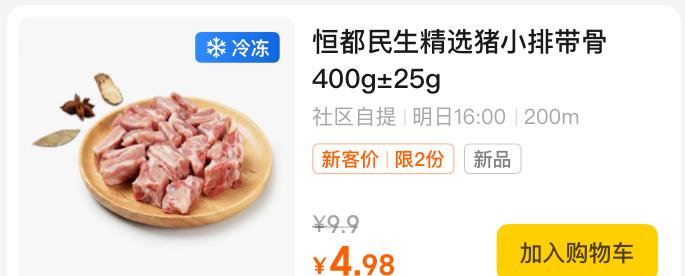 [{“class_name”:”MSTextLayer”,”font_face”:”PingFangSC-Medium”,”font_size”:13.44,”height”:36.5,”index”:8,”line_height”:18.24,”name”:”恒都民生精选猪小排带骨400g±25g”,”object_id”:”EF55F482-A690-4EC2-8A6E-6E7D2C6A9D91″,”opacity”:0.9000000357627869,”text”:”恒都民生精选猪小排带骨400g±25g”,”text_align”:”left”,”text_color”:”#FF000000″,”type”:”text”,”width”:171.8,”x”:164.2,”y”:726.7},//……]2.1.2 组件识别
[{“class_name”:”MSTextLayer”,”font_face”:”PingFangSC-Medium”,”font_size”:13.44,”height”:36.5,”index”:8,”line_height”:18.24,”name”:”恒都民生精选猪小排带骨400g±25g”,”object_id”:”EF55F482-A690-4EC2-8A6E-6E7D2C6A9D91″,”opacity”:0.9000000357627869,”text”:”恒都民生精选猪小排带骨400g±25g”,”text_align”:”left”,”text_color”:”#FF000000″,”type”:”text”,”width”:171.8,”x”:164.2,”y”:726.7},//……]2.1.2 组件识别
从上面的数据源可以看出,图层有图片、文字、矩形等基本类型,在组件识别这一步图层需要被转化成文字/图片/进度条/评分组件/价格组件/角标等日常开发使用的组件类型。但是,目前我们的进展还停留在只能将图层识别为文字或者图片的阶段,后续我们将接入淘宝开源的pipcook框架,基于神经网络算法进行更加丰富的组件类型识别。
2.1.3 可视化干预
设计稿作为输入源是设计稿自动转代码的基础,这对设计稿的设计规范要求较高。但在实践中,我们发现设计师会利用Sketch中的基本图形(每个图形最终形成数据源中的一个图层)叠加来描述一个组件的视觉效果,因此设计稿中不可避免会出现冗余图层的问题,干扰DSL的生成。
虽然我们也尝试了利用自动化的手段删除冗余图层,但对于算法不能识别的部分(例如:图片上有一个文本图层,但是实际情况中文本是显示在图片里的,这个时候无法从算法层面决定是否删除文本),仍然需要靠人工进行图层删除、合并等,否则无法正常生成DSL。设计稿主要有以下几类问题。
图层未合并

上图是从设计稿解析出来的结果,可以发现在“美团优选”文字上方的图片中有很多红色的矩形框(每个矩形框是一个单独的图层),而算法预期的输入是一个图层,因此需要在算法处理前将多个图层合并成一个图层,右侧的三张图也有类似问题。我们与设计同学进行过沟通,设计同学表示愿意在产出设计稿之前将图层进行合并,但由于目前无法提供检测机制(图层合并是否有遗漏无法自动检测出来),也就无法彻底避免图层未合并的问题。
图层位置交叉
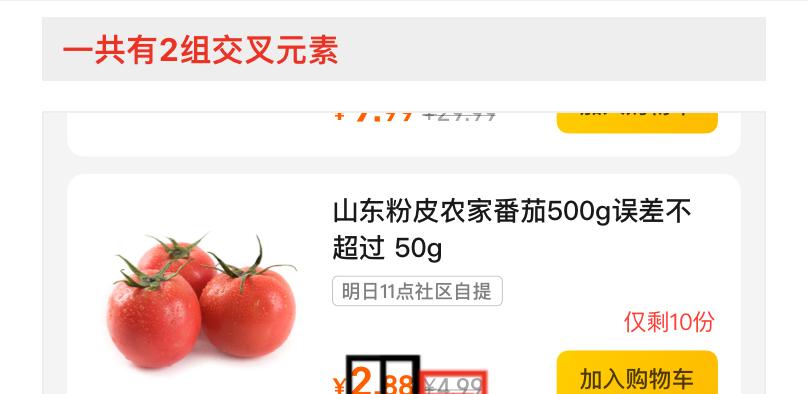
实践中发现当设计稿中不同字体/大小/颜色的文字排列在一起时,解析出来的图层信息往往会出现重叠的情况,由于DSL视图树算法依赖位置来确定不同组件的约束关系,因此位置的交叉会对算法准确度造成较大的影响。
复杂背景图层
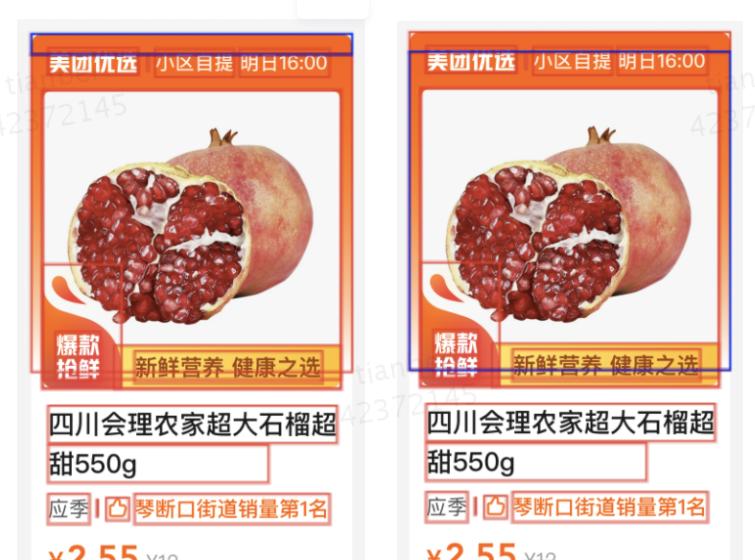
上图中红色背景是由2个图层(2个蓝色矩形框)拼接形成的,左图上的蓝色图层是纯色,右图上的蓝色图层是渐变色,在两个图层未合并的情况下,算法生成的代码将会出错。
上面提出的问题,通过约束设计师来达到设计稿的规范化,难度较大,所以我们提供了可视化干预工具。下面对上述问题做一个简单的总结:
问题一:图层未合并问题肉眼很容易识别出来,利用工具将冗余图层进行快速合并删除即可。问题二:图层交叉问题肉眼不易识别,因此我们提供了检测工具,基于检测工具可以对设计稿中的交叉问题快速修复。问题三:复杂背景问题肉眼不易识别,暂时也没有有效的检测工具,用户可以采用边干预边生成的方式生成DSL。
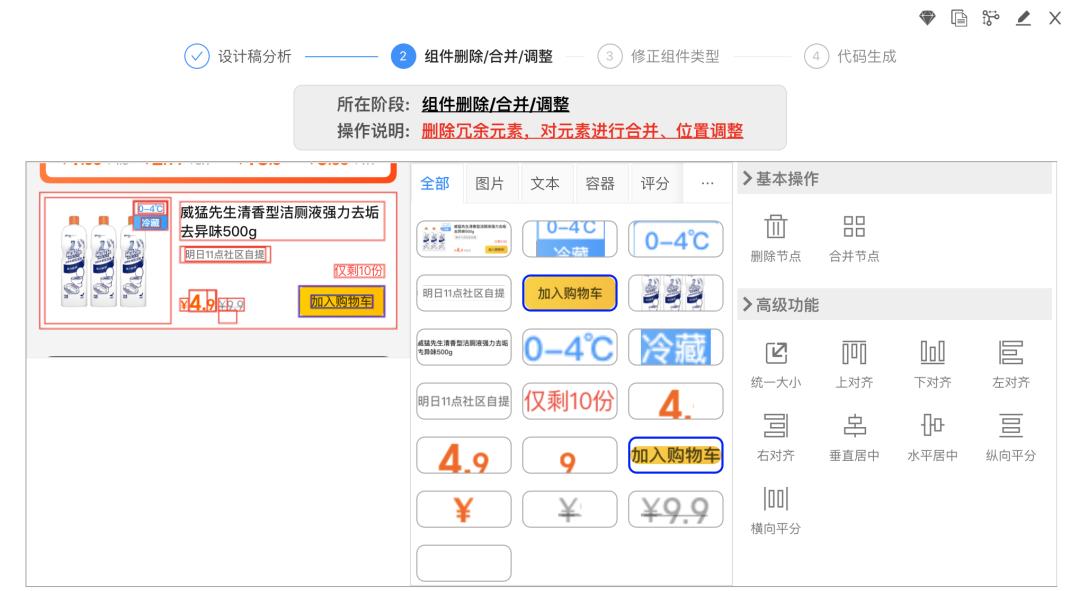
可视化干预是重要的一环,经过可视化干预,将不标准的设计稿转化为标准的图层信息后再输入给算法,可以极大地提升算法的准确率。这里我们和imgCook的处理方式有一个区别:imgCook在引入了阈值处理等算法后(更智能,出错概率更大),可视化干预能力主要体现在事后,而我们在生成DSL之前允许用户对图层进行干预,在干预时用户面对的是直观的图层信息,可以有效降低工具的使用门槛(更稳定,效果更好)。
2.1.4 视图树生成
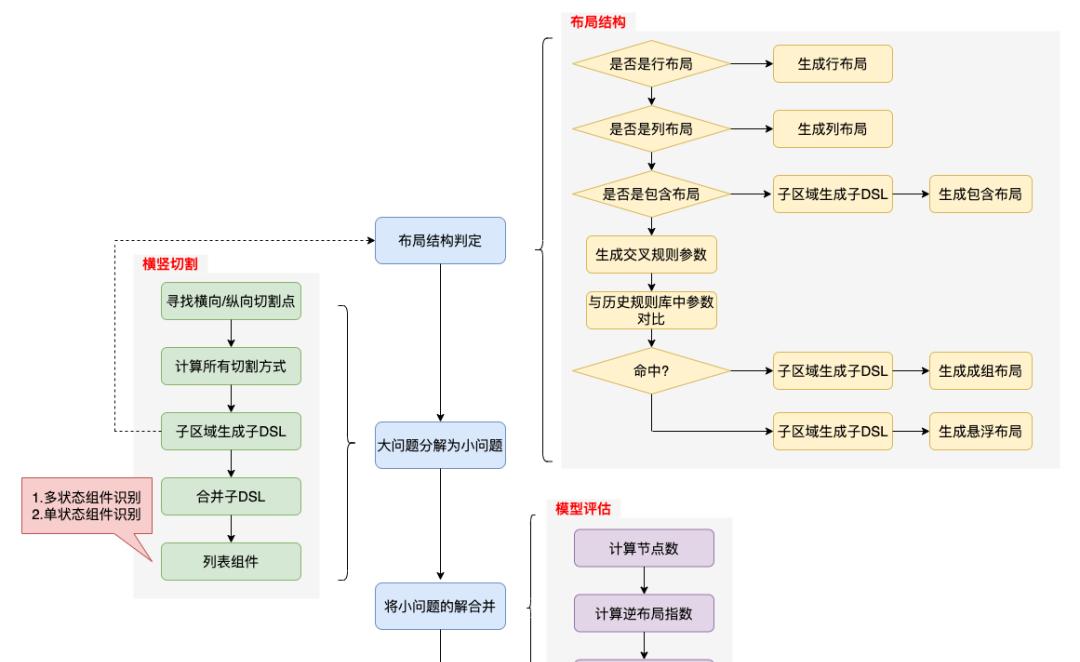
将扁平的数据源转化为树状结构的DSL,这个过程如果是人脑来做会怎么思考呢?先确定布局的整体结构是行布局或者列布局,然后再确定局部区域应该是什么布局结构,最后组装起来形成视图树。这个过程与递归算法类似,因此我们采用了递归算法作为算法的主框架,同时引入了“横竖切割 布局结构 模型评估”三大利器。
利器一:横竖切割
生成DSL时采用了整分的思路,即将大布局不断的切分成小布局,下面以动画的形式看一下简化过的DSL生成过程:
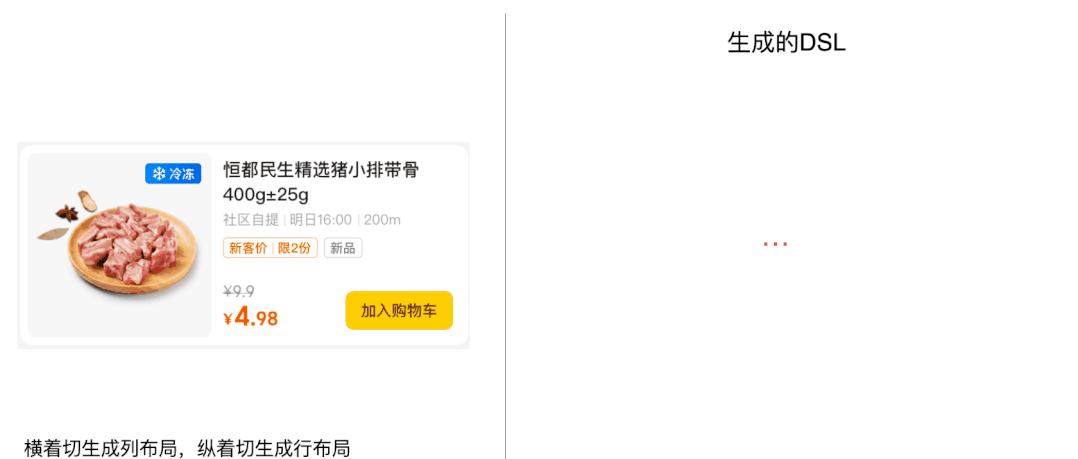
将设计稿一部分区域视为一个子区域,最开始的时候子区域和整个模板的面积一样大,基于图层的位置、大小信息,计算每个图层的上/下/左/右边缘坐标与其他图层的相对关系,就可以寻找到切割点(如上图中红色箭头所指的位置)。接下来依据切割点,将子区域切割成更小的子区域,在切割的过程中如果切割点是横向的,则生成列布局;如果切割点是纵向的,则生成行布局。通过不断的切割子区域得到更小的子区域,直到所有的子区域只剩下图片或者文本等不可切割的图层,这样就可以生成完整的DSL视图树了。为了方便读者理解,图例中只演示了行布局、列布局的切分过程,实际情况还包含了其他布局类型,会要复杂许多。
这里还要注意一个问题,当有3个切割点时,我们选择了直接将子区域切割成4个子区域,实际上我们可以只选择1个切割点进行切割,也可以选择2个切割点进行切割,当有N个切割点时,实际上存在(N的阶乘 1)种切割方式,具体选择哪种切割方式,我们会在利器三中讨论。
利器二:布局结构
每个图层都是一个矩形,为了生成布局结构只能依赖矩形的上下左右坐标信息。因此,对布局结构进行分类时,我们根据矩形与矩形之间的位置关系(相交、相离和包含关系)做了以下分类。
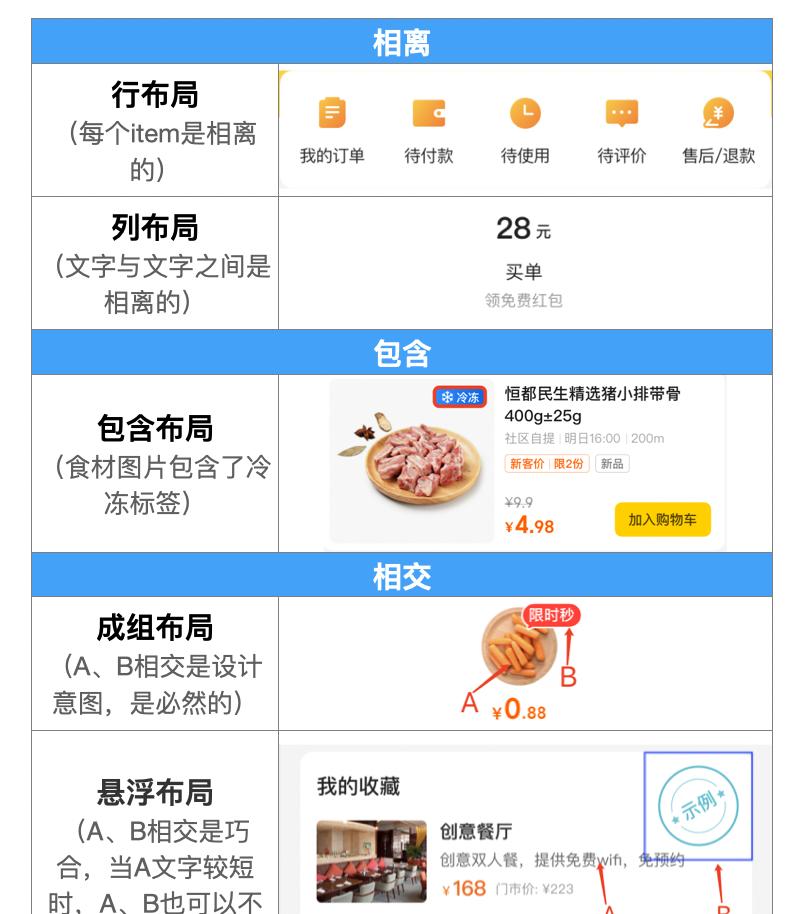
注意:从生成DSL的结果来看,包含布局和成组布局的处理方式其实是一样的,都是使用类似于FrameLayout的层叠布局包含内部图层元素,但是我们仍然保持分类原则(矩形之间的位置关系)不变。
上图中,相离、包含比较好理解,为什么两个图层相交的时候,会有成组和悬浮两种类型的布局结构呢?我们看下上述成组布局、悬浮布局两个设计稿中分别标出了相交的元素A、B,它们在位置上的相对关系是一样的,都是A、B两个图层对应的矩形框发生了交叉。但是我们希望理想态的DSL视图树却有所差异,如下图所示:
成组布局中:A、B逻辑上是一个整体,交叉是必然的,最终DSL中A、B被层叠布局包含,层叠布局中没有其他元素。悬浮布局中:A、B逻辑上不是整体,只是碰巧交叉了,最终DSL中A、B分别在不同的层级中。
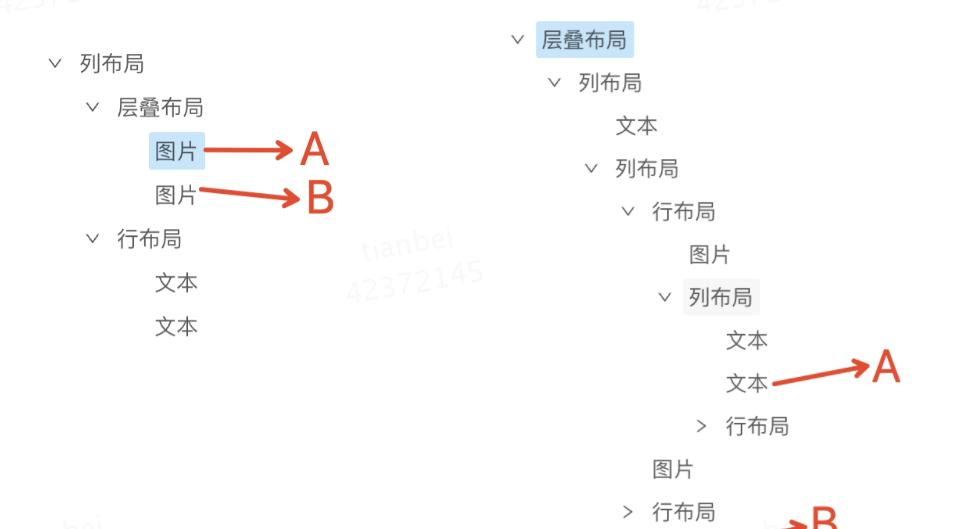
因此,对于图层相交时可能有两种类型的布局结构,分别是成组布局和悬浮布局。从上图可以看出使用成组布局还是悬浮布局是由图层内容决定的,那么就需要算法理解图层内容了,比如基于AI构建样本库,记住所有的角标样式(上面表格中4描述的),下次遇到角标相交时就生成成组布局。
考虑到AI模型也是对规则的抽象,我们先搭建一套自定义识别规则。成组布局其位置信息是有规律可循的,例如:角标经常出现在右上角,标签经常出现在左上角,头像经常横向或者纵向交叉等,因此我们针对图层之间的位置关系构建了交叉模型,如下图所示:
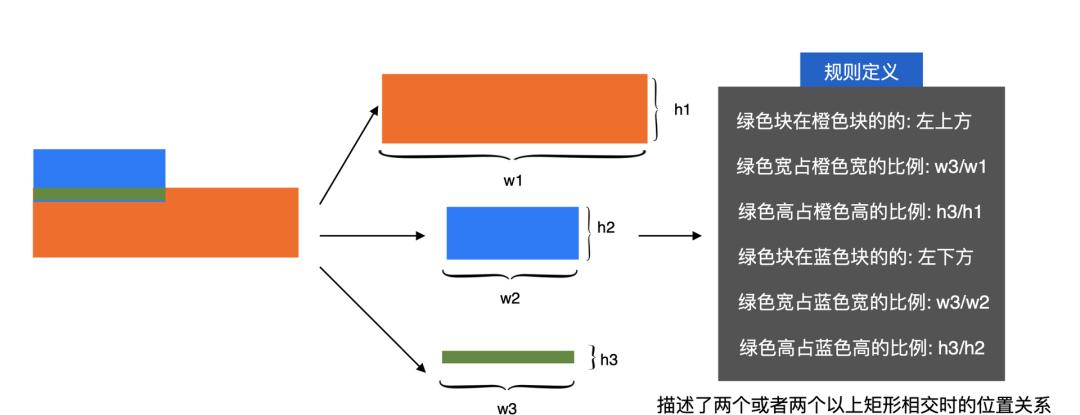
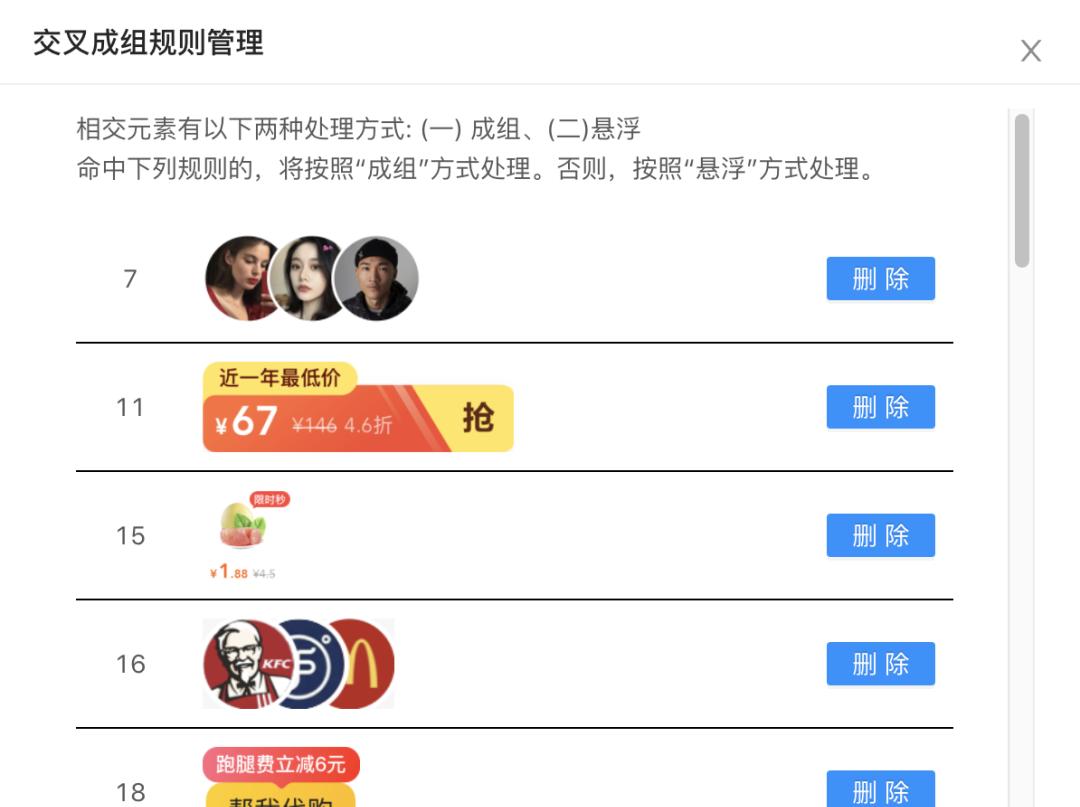
上图的交叉模型可以记住历史模板中成组布局图层之间的位置关系,下次遇到相交布局时判断是否在历史规则库中即可完成识别,如果在就按成组布局处理否则按照悬浮布局处理。下图是通过历史模板构建的成组规则库。
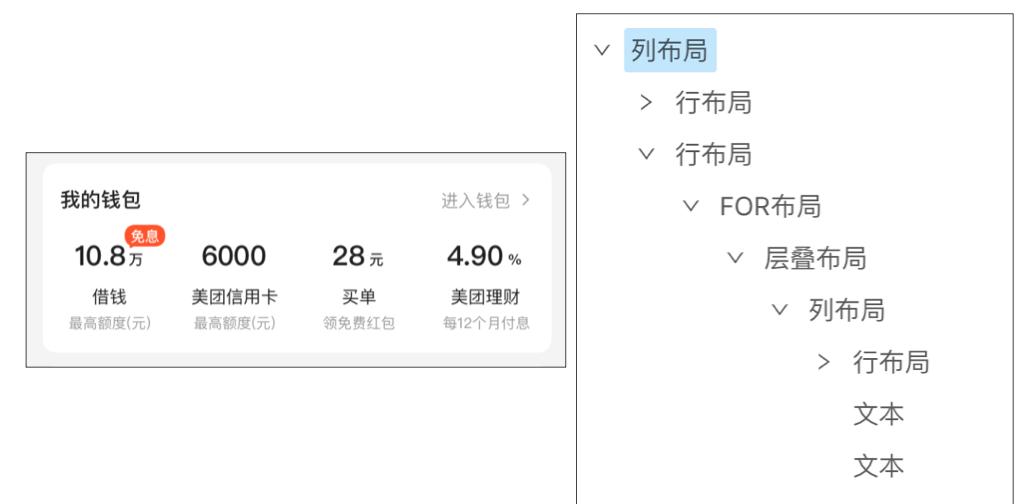
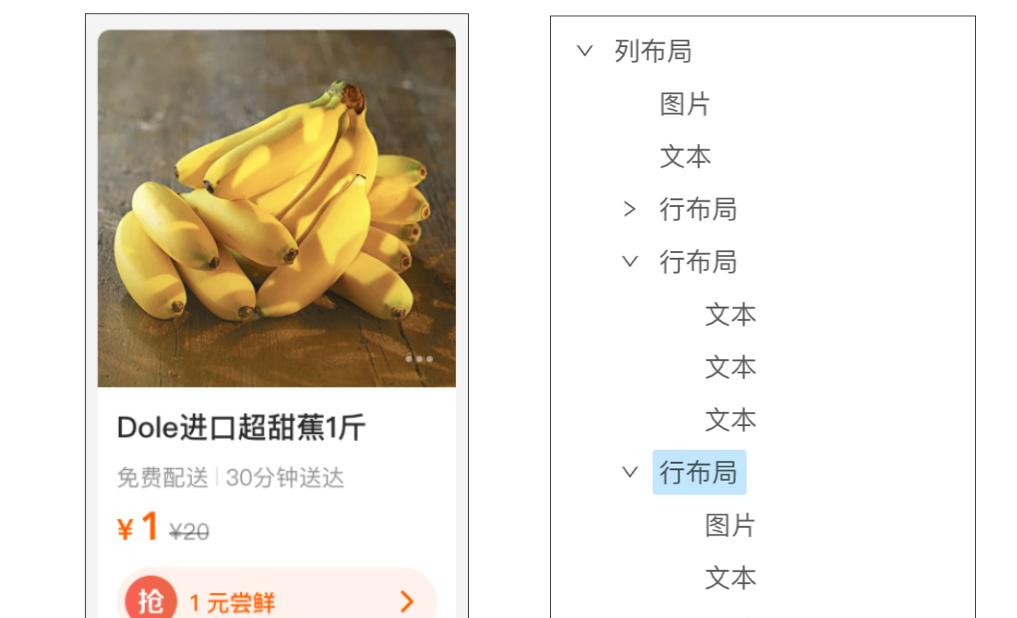
上面介绍了本方案中涉及的5种布局类型,目前来看这五种布局类型可以描述所有的模板布局,并且生成代码符合RD的预期。下面展示两个设计稿DSL实例:
利器三:模型评估
在介绍横竖切割时,可以看到当存在多个切割点时,对所有切割点同时进行了切割,但实际上算法在切割时复杂度会更高,当有三个切割点时,实际上有5种切割方式,每种切割方式都会生成一个DSL。既然有5种切割方式,那么到底应该选择哪一种DSL呢?模型评估算法就是用来解决这个问题的。
目前模型评估算法有两个指标:布局节点数和逆布局指数。
DSL中布局节点数越少,切割方式越好。逆布局指数用来评估DSL中的行列布局的合理程度,其中逆布局指数越大越不合理,反之,逆布局指数越小,切割方式越好。
以下图为例,看下视图不同切割方式下对应的模型评估方式:

如果模型评估算法只衡量布局节点数的话,那么会选择第一种切割方式生成的DSL作为最终的结果。但实际上,第二种切割方式更加合理。在切割方式一中,广告、立即预约处于一个列布局中,但是横向对齐方式(交叉轴)却不一样,“广告”是右对齐,“立即预约”是左对齐,逆布局指数表示交叉轴对齐方式不一致的节点数量,因此通过逆布局指数,我们可以规避掉不合理的切割方式。
2.1.5 列表布局
上一节介绍了基本的布局结构,虽然说这些布局结构已经可以描述所有的UI布局,但是与RD的编码习惯还是有一些差异。

对于上面的布局,RD通常不会把相同的item写五遍,而是会将item放在一个类似于ListView的列表组件中,使代码看起来简洁易懂。因此在DSL生成阶段,除了识别基本的行/列/包含/成组/悬浮布局外,还需要进一步识别行/列布局中的元素是否形成列表布局。
在试验过程中,我们发现列表布局分为两种:单状态列表组件和多状态列表组件。上图中每一个item的布局结构都是一样的,我们称为单状态列表组件,再来看一下多状态列表组件(如下图所示),每个item有多种状态(选中态和非选中态),并且不同状态的布局结构不一致。

对行/列布局中单状态列表组件的识别,只需要比较item子视图树的结构,子视图树结构一致则判断为单状态列表组件。对多状态列表组件的识别我们采取了自动识别 人工干预的方式,自动识别的方式比较粗暴,只要行列布局中子item的宽/高接近,并且子item不是基本组件(基本组件容易形成误判),就判定为多状态列表组件。具体算法是计算子item宽高的标准差,小于阈值就判定为多状态列表组件,否则不是。公式如下:
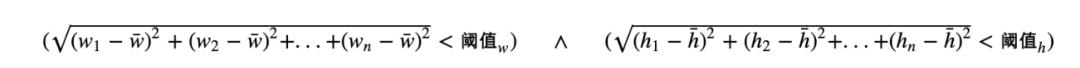
那为什么还要人工干预呢?因为是否使用列表组件其实与产品逻辑相关,但是目前我们无法将产品文档中的逻辑识别出来,只能尽可能识别出所有的多状态列表组件,并允许用户对生成结果进行变更。比如上述送恋人的设计稿,产品可能约定每一个item都有选中态/非选中态两种状态,也可能是从业务角度考虑需要着重突出送恋人这个item,这时每个item就只有一种确定的状态,这两种不同的产品逻辑在编写代码时有不同的最优技术方案。
2.2 视图树转代码(DSL2Code)
DSL视图树只是生成代码的中间产物,还需要对DSL进行代码还原,DSL2Code主要包括两个步骤:属性推断、属性信息调整。
2.2.1 属性推断
属性推断包括两个部分:样式属性和结构属性。样式属性包括字体、背景色、圆角等可以直接通过数据源信息中获取得到的属性;结构属性包括大小、内外边距、主辅轴对齐等结构信息,这些信息无法从数据源中直接获取,所以结构信息的推断是这部分工作的重点。
结构信息推断算法同样使用递归算法作为主框架,通过一次递归对所有元素进行两次遍历来完成结构信息的推断。如下图所示,在对DSL所有节点进行递归遍历时,把所有元素依次加入队列中,递归完成后,再把所有节点依次移出队列,这样一进一出便对所有元素完成了两次遍历,我们把这两次遍历称为进队遍历和出队遍历。
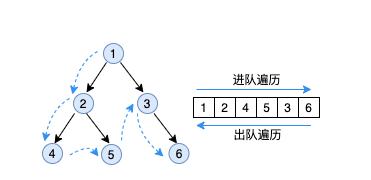
进队遍历时,推断算法根据数据源中信息记录每个节点的大小和位置信息,并根据位置关系计算每个子节点在父节点中期望的主辅轴对齐方式和内外边距。出队遍历时,父节点会根据子节点期望的对齐方式确定父节点最终的主辅轴对齐方式,并根据子节点的拉伸意图修正父节点的大小。拉伸意图即节点的大小不固定,根据显示内容不同,在水平或垂直方向上可能会变大或变小,例如文本节点根据显示字数的多少长度会发生变化,字数过多时甚至还会换行。
2.2.2 属性信息调整
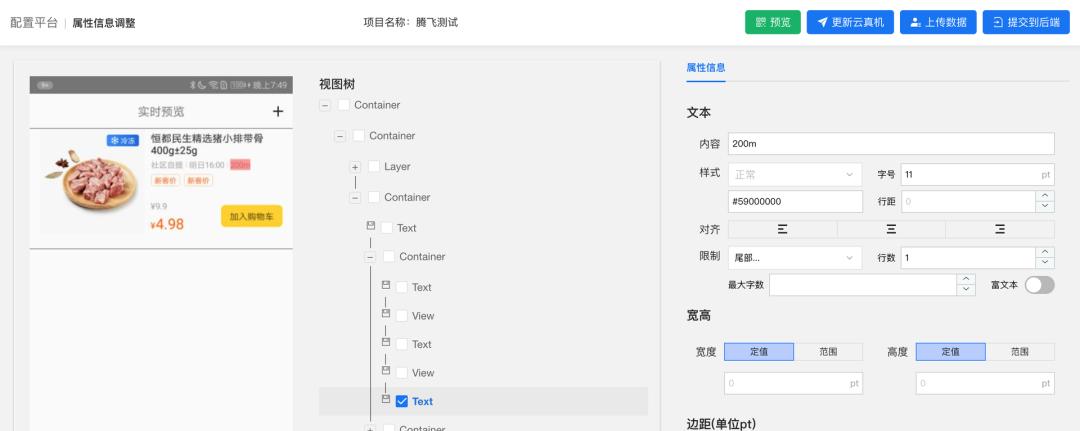
由于输入源是基于设计稿呈现的静态效果图,设计稿中每个元素缺失了真实的业务含义,同样的展示效果在不同的业务场景中会有不同的属性要求,对于这部分内容,我们无法从输入源中进行准确推断。为此,我们提供了可视化的属性信息调整功能来辅助代码生成,页面效果如下图所示,在这个页面可以对DSL中的所有节点属性进行查看和修改调整。
经过业务信息补充后,便可进行最后的自动代码转化,通过语法映射自动把DSL转化成MTFlexbox模板代码。
3 成果展示
下面是设计稿直接生成代码未经修改展示后的手机屏幕截图,可以看到取得了不错的还原效果:
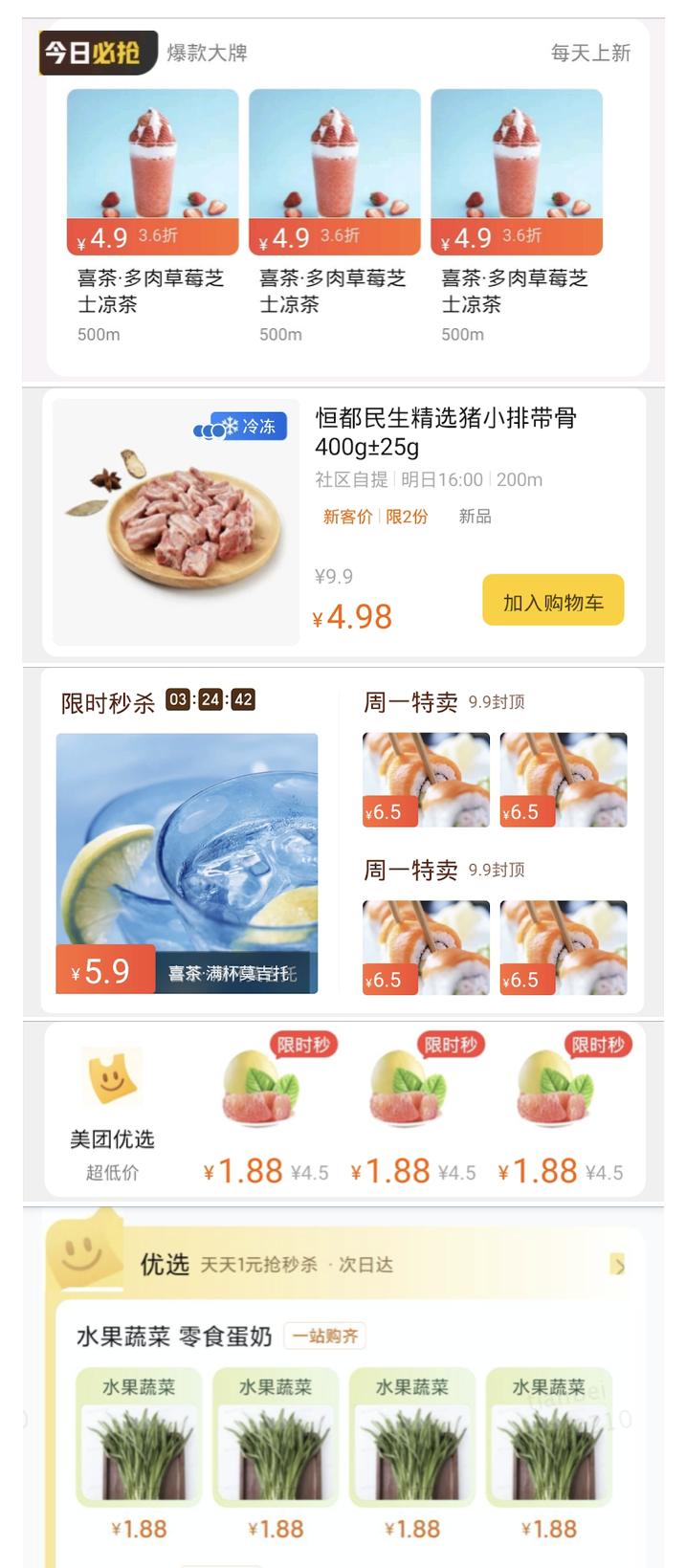
以上就是我们近期对代码自动生成的探索及实践,后续我们将引入机器学习及神经网络算法,对过程进行进一步优化。如果您有其他的看法或建议,也欢迎在文末进行评论,或者跟我们联系。
田贝、少宽、腾飞等,美团平台终端业务研发团队研发工程师。
———- END ———-招聘信息美团平台终端业务研发团队的职责是保障平台业务高效、稳定迭代的同时,持续优化用户体验和研发效率。团队负责的业务主要包括美团首页等千万级DAU高频业务以及分享、账号、音/视频等基础业务,支撑和对接外卖、酒店等30多个业务方。团队通过动态化能力建设,加快业务上线速度,帮助产品(PM)快速验证业务选型,做出业务决策;架构/服务标准化体系建设,提升前后端以及平台与业务线的沟通、合作效率;业务监控和体验优化,有效保障核心业务服务成功率的同时,提升用户使用美团App过程中的稳定性和流畅性。团队开发技术栈包括Android、iOS、React Native、Flexbox等。美团平台终端业务研发团队是一个活力四射、对技术充满激情的团队,现诚聘Android、iOS、FE工程师,欢迎有兴趣的同学投简历至tech@meituan.com(备注:美团平台终端业务研发团队)。也许你还想看 |积木Sketch插件进阶开发指南 |积木Sketch Plugin:设计同学的贴心搭档 |AI技术在智能海报设计中的应用









